
L’une des premières tâches que l’on m’a confiées lorsque j’ai commencé à travailler en tant que Data Scientist (Expert en Mégadonnées) a nécessité que Je fasse du web scraping (encore appelé harvesting et grattage web par certains).
C’était un concept qui m’était complètement étranger à l’époque et qui consiste à recueillir des données à partir de sites Web en utilisant un code, mais c’est en réalité l’une des sources de données les plus logiques et les plus facilement accessibles.
Après quelques essais, le web scraping avec python est devenu pour moi une seconde nature et l’une des nombreuses compétences que j’utilise presque quotidiennement.
Dans ce tutoriel, je vais expliquer en me servant d’un exemple simple, la façon de scraper un site web pour recueillir des données sur les 100 meilleures entreprises ‘Fast Track’ en 2018. L’automatisation de ce processus à l’aide d’un web scraper permet d’éviter la collecte manuelle de données, de gagner du temps et de regrouper toutes les informations sur les entreprises dans un seul fichier structuré.
[TL;DR]* Pour un exemple rapide d’un simple web scraper avec python, vous pouvez trouver le code complet dont parle ce tutoriel sur GitHub.
Pour commencer
La première question à se poser avant de commencer à utiliser une application python est « De quelles bibliothèques ai-je besoin ? »
Pour le web scraping, il y a plusieurs bibliothèques qui peuvent être utilisées, notamment :
- Beautiful Soup
- Requests
- Scrapy
- Selenium
Pour le présent exemple, nous utiliserons Beautiful Soup. En utilisant pip, le gestionnaire de paquets Python, vous pouvez installer Beautiful Soup avec ce qui suit :
pip install BeautifulSoup4
Maintenant que ces bibliothèques sont installées, nous pouvons commencer !
Inspectez la page Web
Pour savoir quels éléments vous devez cibler avec votre code python, vous devez d’abord inspecter la page web.
Pour recueillir des données du Top 100 des entreprises de Tech Track, vous pouvez inspecter la page en cliquant avec le bouton droit de la souris sur l’élément qui vous intéresse et en sélectionnant Inspecter. Ceci fait apparaître le code HTML où on peut voir l’élément dans chaque champ qui le contient.
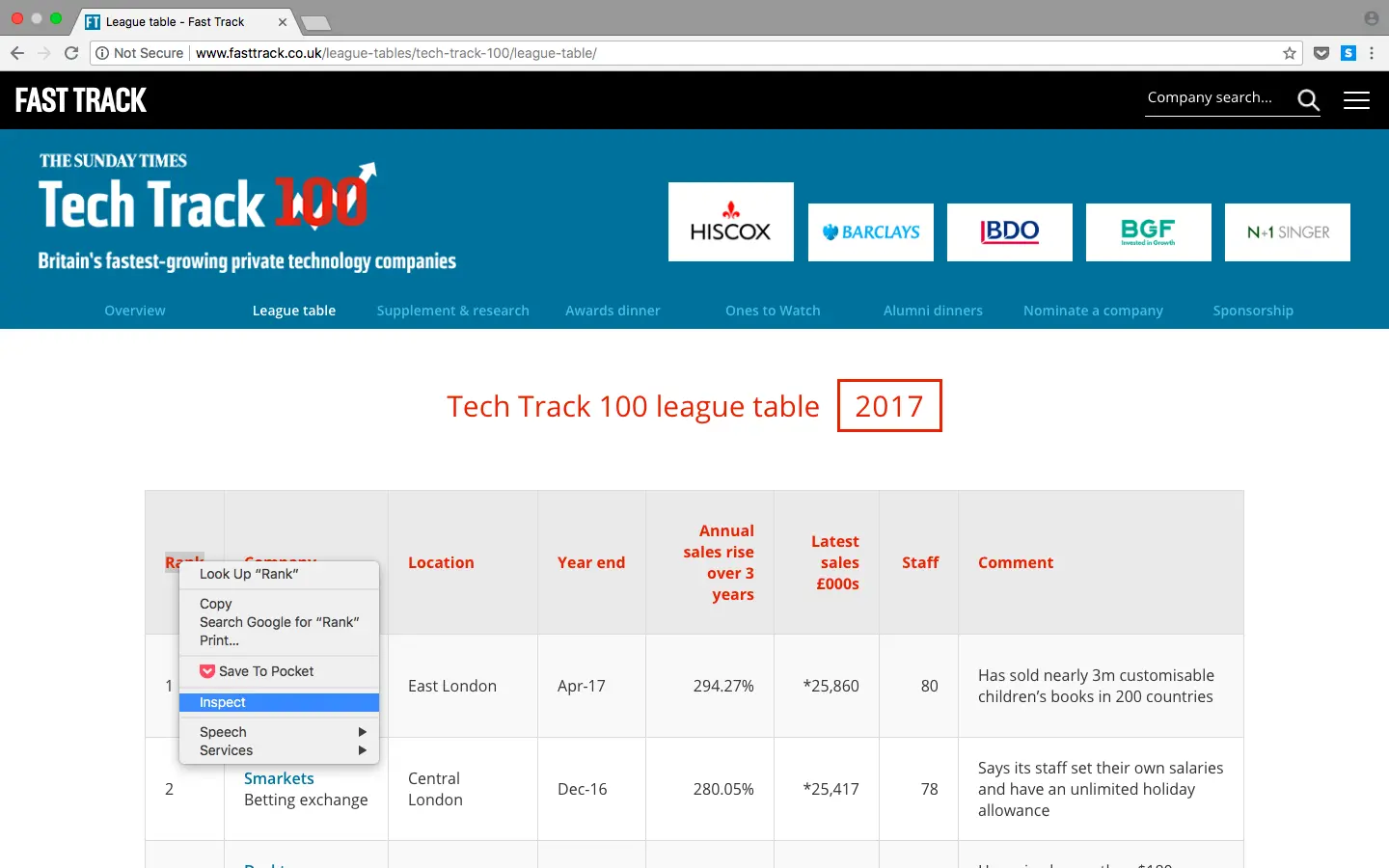
Right click on the element you are interested in and select ‘Inspect’, this brings up the html elements
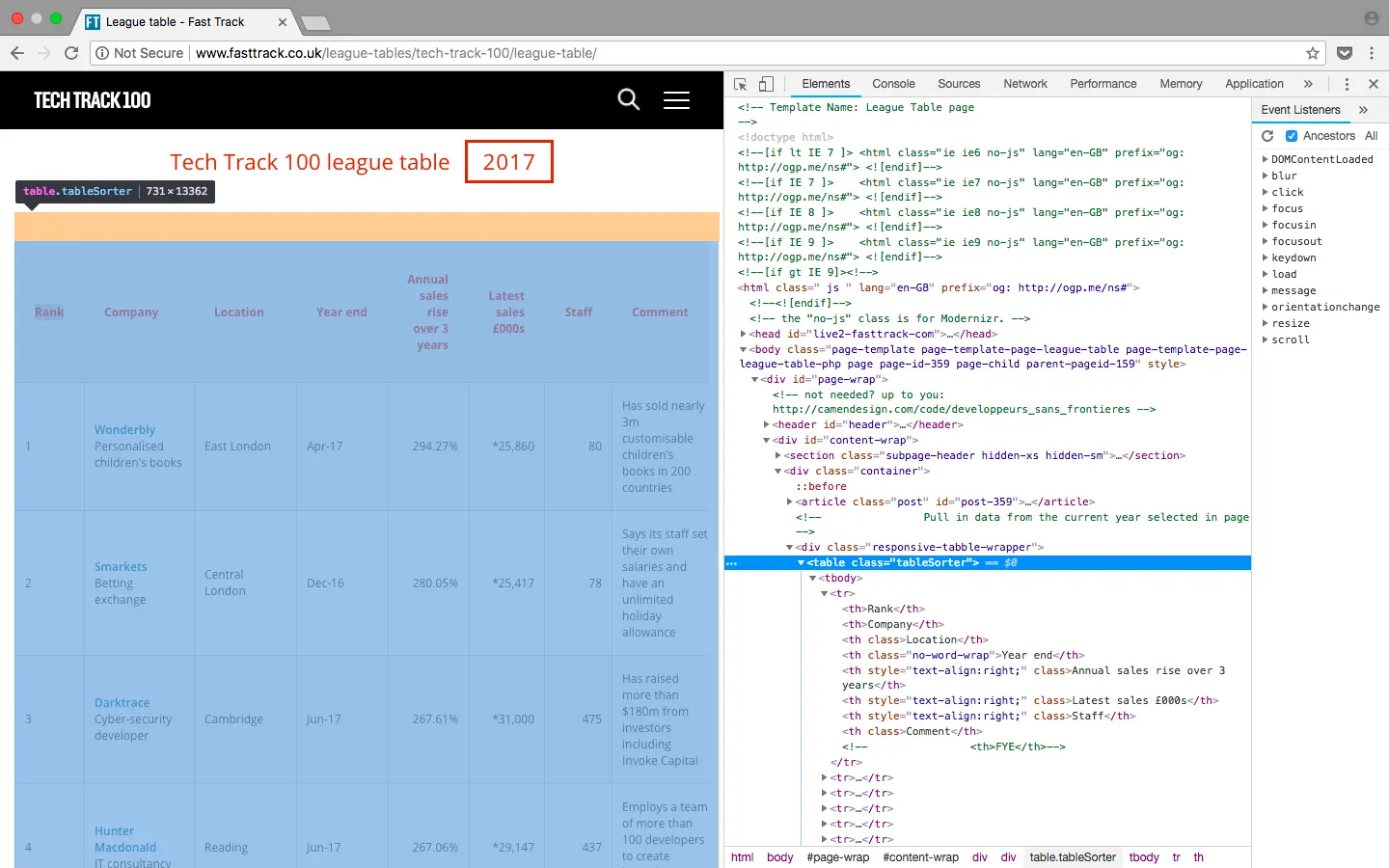
Tous les 100 résultats sont contenus à l’intérieur de lignes dans des éléments Sur la page web de la League Table, un tableau contenant 100 résultats est affiché. Lors de l’inspection de la page, il est facile de voir un schéma se répéter dans le html. Les résultats sont présentés sous forme de lignes dans le tableau : Les lignes Remarque : Une autre vérification à faire est de voir si une requête HTTP GET est en train d’être faite sur le site Web, ce qui peut déjà renvoyer les résultats sous forme de réponse structurée comme dans un format JSON ou XML. Vous pouvez effectuer cette vérification à partir de l’onglet réseau (Network) dans les outils d’inspection, souvent dans l’onglet XHR. Une fois qu’une page est rafraîchie, elle affiche les requêtes de la façon dont elles se chargent, et si la réponse contient une structure formatée, il est souvent plus facile de lancer une requête en utilisant un client REST tel que Insomnia pour retourner le résultat. Maintenant que vous avez regardé la structure du html et que vous vous êtes familiarisé avec ce que vous scrapez, il est temps de commencer à utiliser python ! La première étape est d’importer les bibliothèques que vous utiliserez pour votre web scraper. Nous avons déjà parlé de Beautiful Soup ci-dessus qui nous aide à gérer le html. La prochaine bibliothèque que nous importerons est urllib qui permet d’établir une connexion avec la page web. Aussi, les résultats seront inscrits dans un CSV, ce qui fait que nous avons aussi besoin d’importer la bibliothèque csv. Comme alternative, la bibliothèque json pourrait être utilisée à la place. L’étape suivante consiste à définir l’URL que vous voulez scraper. Comme nous l’avons vu dans la section précédente, cette page Web présente tous les résultats sur une seule page. Ainsi, vous devez fournir l’URL complète ici, comme dans la barre d’adresse. Nous faisons ensuite la connexion à la page web avec urllib, puis nous pouvons analyser le html avec BeautifulSoup, en stockant l’objet dans la variable « Soup ». Nous pouvons afficher la variable soup à ce stade, ce qui devrait donner le html complet analysé de la page web que nous avons demandée. S’il y a une erreur ou si la variable est vide, il se peut que la requête n’ait pas abouti. Vous pourriez vouloir implémenter la gestion des erreurs à ce stade en utilisant le module urllib.error. Comme tous les résultats sont contenus dans une table, nous pouvons rechercher l’objet soup de la table en utilisant la méthode find. Nous pouvons alors trouver chaque ligne à l’intérieur de la table en utilisant la méthode find_all. Si nous affichons le nombre de lignes, nous devrions obtenir un résultat de 101 : les 100 lignes plus l’en-tête. Nous pouvons donc faire une boucle sur les résultats afin de recueillir les données. En affichant les 2 premières lignes de l’objet soup, on peut voir que la structure de chaque ligne est : Il y a 8 colonnes dans le tableau avec les informations suivantes : Rang, Société, Emplacement, Fin d’année, Augmentation des ventes annuelles, Dernières ventes, Personnel et Commentaires (Rank, Company, Location, Year End, Annual Sales Rise, Latest Sales, Staff and Comments). Ce sont toutes des données intéressantes que nous pouvons sauvegarder. Cette structure se répète pour toutes les lignes de la page web (ce qui n’est pas toujours le cas pour tous les sites web !), et pour cela, nous pouvons donc à nouveau utiliser la méthode find-all pour affecter chaque colonne à une variable que nous pouvons écrire dans un csv ou JSON en cherchant l’élément En python, il est utile d’ajouter les résultats à une liste pour ensuite écrire les données dans un fichier. Nous devrions déclarer la liste et mettre les en-têtes du CSV avant la boucle avec ce qui suit : Ceci affichera la première ligne que nous avons ajoutée à la liste contenant les en-têtes. Vous remarquerez certainement qu’il y a quelques champs supplémentaires Webpage et Description qui ne sont pas des noms de colonnes dans le tableau, mais si vous regardez de plus près le html de lorsque nous avons imprimé la variable soup ci-dessus, la deuxième ligne contient plus que le simple nom de la société. Nous pouvons procéder à des extractions complémentaires pour obtenir ces informations supplémentaires. L’étape suivante est de faire une boucle sur les résultats, de traiter les données et de les ajouter aux lignes qui peuvent être écrites dans un fichier CSV. Pour trouver les résultats dans la boucle : Etant donné que la première ligne du tableau ne contient que les en-têtes, nous pouvons ignorer ce résultat, comme indiqué ci-dessus. Il ne contient pas non plus d’éléments Nous pouvons alors commencer à traiter les données et à les sauvegarder dans des variables. Le code ci-dessus récupère simplement le texte de chacune des colonnes et l’enregistre dans les variables. Certaines de ces données doivent toutefois être nettoyées plus en profondeur pour supprimer les caractères indésirables ou pour extraire des informations complémentaires. Si nous affichons la variable ‘company’, le texte contient non seulement le nom de la société, mais aussi une description. Si nous affichons ensuite sales, il contient des caractères indésirables tels que des symboles de note de bas de page qu’il serait utile de supprimer. Pour séparer company en deux champs, nous pouvons utiliser la méthode find pour enregistrer l’élément et ensuite utiliser strip ou replace pour supprimer le nom de la société de la variable company, afin qu’il n’y reste que la description. Pour supprimer les caractères indésirables de sales, nous pouvons à nouveau utiliser les méthodes strip et replace ! La dernière variable que nous aimerions sauvegarder est le site web de l’entreprise. Nous l’avons mentionné plus haut, la deuxième colonne contient un lien vers une autre page qui donne plus de détails sur chaque société. En fait, chaque page d’entreprise a son propre tableau qui, la plupart du temps, contient le site web de l’entreprise. Pour scraper l’URL de chaque tableau et l’enregistrer comme variable, nous devons utiliser les mêmes étapes que ci-dessus : Lorsqu’on regarde quelques pages de l’entreprise, comme sur la capture d’écran ci-dessus, les url sont dans la dernière ligne du tableau, ce qui nous permet de chercher l’élément dans la dernière ligne. Il peut également y avoir des cas où le site web de la société n’est pas affiché. Nous pouvons alors placer une clause try except, au cas où une url serait introuvable. Une fois que nous avons sauvegardé toutes les données dans des variables, toujours dans la boucle, nous pouvons ajouter chaque résultat à la liste lignes. Il est alors utile d’afficher la variable en dehors de la boucle, pour vous assurer qu’elle est conforme à ce que vous attendez avant de l’écrire dans un fichier ! Vous pourriez vouloir sauvegarder ces données pour analyse, et cela peut être fait très simplement via python à partir de notre liste. Lors de l’exécution du script python, votre fichier de sortie sera généré contenant 100 lignes de résultats que vous pourrez consulter de manière plus détaillée ! Ce bref tutoriel sur le web scraping avec python a montré comment : C’est mon premier tutoriel, alors faites-moi savoir si vous avez des questions et laissez un commentaire si vous ne comprenez pas quelque chose ! *TL;DR : en anglais: ‘too long, didn’t read’ ou en français: ‘trop longue à lire’ et ils sont tous visibles sur la même page. Cela ne sera pas toujours le cas, et si les résultats s’étendent sur plusieurs pages, vous devrez modifier le nombre de résultats affichés sur une page ou mettre en place une boucle sur toutes les pages pour collecter la totalité des informations que vous recherchez. 
répétées nous permettront de nous servir d’un code de base en utilisant une boucle dans python pour trouver les données et les inscrire dans un fichier !
Analyser le code html de la page web en utilisant Beautiful Soup
# import libraries
from bs4 import BeautifulSoup
import urllib.request
import csv
# specify the url
urlpage = 'http://www.fasttrack.co.uk/league-tables/tech-track-100/league-table/'
# query the website and return the html to the variable 'page'
page = urllib.request.urlopen(urlpage)
# parse the html using beautiful soup and store in variable 'soup'
soup = BeautifulSoup(page, 'html.parser')
print(soup)
Recherche d’éléments HTML
# find results within table
table = soup.find('table', attrs={'class': 'tableSorter'})
results = table.find_all('tr')
print('Number of results', len(results))
Rank
Company
Location
Year end
Annual sales rise over 3 years
Latest sales £000s
Staff
Comment
1
WonderblyPersonalised children's books
East London
Apr-17
294.27%
*25,860
80
Has sold nearly 3m customisable children’s books in 200 countries
Th
.
Mise en place d’une boucle sur les éléments et sauvegarde des variables
# create and write headers to a list
rows = []
rows.append(['Rank', 'Company Name', 'Webpage', 'Description', 'Location', 'Year end', 'Annual sales rise over 3 years', 'Sales £000s', 'Staff', 'Comments'])
print(rows)
# loop over results
for result in results:
# find all columns per result
data = result.find_all('td')
# check that columns have data
if len(data) == 0:
continue
, ce qui veut dire que lors de la recherche de l’élément, aucun résultat n’est retourné. Nous pouvons alors vérifier que seuls les résultats contenant des données sont traités en exigeant que la longueur des données soit non nulle.
# write columns to variables
rank = data[0].getText()
company = data[1].getText()
location = data[2].getText()
yearend = data[3].getText()
salesrise = data[4].getText()
sales = data[5].getText()
staff = data[6].getText()
comments = data[7].getText()Nettoyage des données
print('Company is', company)
# Company is WonderblyPersonalised children's books
print('Sales', sales)
# Sales *25,860
Nous aimerions diviser company en deux parties : le nom de la société et la description ; ce que nous pouvons faire en quelques lignes de code. En regardant à nouveau le html, pour cette colonne, il y a un élément qui contient seulement le nom de la société. Il y a également un lien dans cette colonne vers une autre page du site Web qui contient des informations plus détaillées sur l’entreprise. Nous nous en servirons un peu plus tard !
http://www.fasttrack.co.uk/company_profile/wonderbly-3/">WonderblyPersonalised children's books
# extract description from the name
companyname = data[1].find('span', attrs={'class':'company-name'}).getText()
description = company.replace(companyname, '')
# remove unwanted characters
sales = sales.strip('*').strip('†').replace(',','')
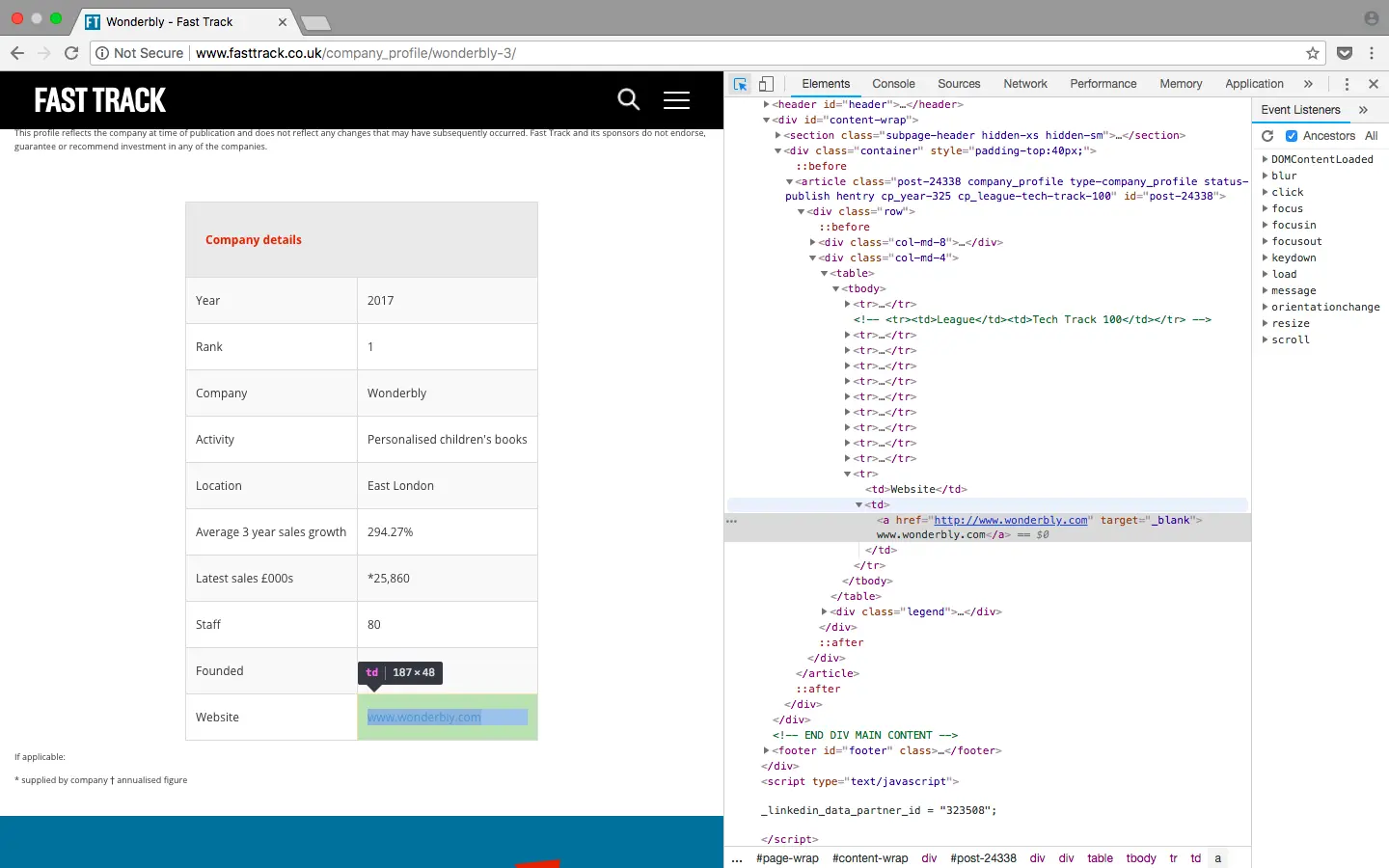
# go to link and extract company website
url = data[1].find('a').get('href')
page = urllib.request.urlopen(url)
# parse the html
soup = BeautifulSoup(page, 'html.parser')
# find the last result in the table and get the link
try:
tableRow = soup.find('table').find_all('tr')[-1]
webpage = tableRow.find('a').get('href')
except:
webpage = None
# write each result to rows
rows.append([rank, companyname, webpage, description, location, yearend, salesrise, sales, staff, comments])
print(rows)
Écrire dans un fichier de sortie
# Create csv and write rows to output file
with open('techtrack100.csv','w', newline='') as f_output:
csv_output = csv.writer(f_output)
csv_output.writerows(rows)
Résumé
![]()
About kerry parker
Reader Interactions
Comments
Leave a Reply
 Capgemini au concours du Meilleur Développeur de France 2019 : pour et avec les développeurs
Capgemini au concours du Meilleur Développeur de France 2019 : pour et avec les développeurs
Saurait été mieux en vidéo, en fait j’ai un site écrit en HTML CSS bootstrap, du coup j’ai une barre de recherche et j’aimerais faire des recherches interne sur mon site, avec l’outil python, sa sera possible de scraper ??
Pour ceux qui ont des problèmes avec urllib l’erreur 403 il suffit de remplacer la librairie urllib par la librairie requests puis de remplacer le page = urllib.request.urlopen(urlpage) par page = requests.get(urlpage) et le soup = BeautifulSoup(page, ‘html.parser’) par soup = BeautifulSoup(page.text, ‘html.parser’)
Merci. Très clair , reste plus qu’ a tester sur d autres sites.
Bonjour
merci pour ce très bon tuto, juste une question, si une cellule est vide comment éviter un décalage du CSV
cordialement
bonjour, tout à l’air si simple.. mais quand on met les mains dans le moteur alors qu’on est pas technicien.. bravo pour ce petit tuto..