

Python est un langage de programmation populaire et polyvalent, apprécié pour sa simplicité et sa clarté. Que le développeur soit débutant ou expérimenté, avoir un guide pratique sous la main est un véritable atout pour l’aider à accomplir des tâches courantes plus efficacement.
Cet aide-mémoire Python ultime a été conçu pour être son compagnon fiable, lui permettant de naviguer à travers les fonctionnalités essentielles du langage.
Des opérations de base sur les fichiers jusqu’à l’utilisation des modules populaires, en passant par la programmation orientée objet, ce guide lui fournira les snippets de code, les explications et les exemples dont il a besoin.
Que le développeur cherche à automatiser des tâches, manipuler des données, ou créer des applications web, cette ressource complète sera son alliée indispensable.
Travailler avec des Fichiers
Python offre une multitude de commandes interagir avec des fichiers. Ces commandes englobent la lecture, l’écriture et la gestion de fichiers de manière simple et intuitive. Parmi celles-ci, l’on en compte dix indispensables.
1. Ouvrir un fichier avec la fonction ‘open()’
Avant d’entamer n’importe quelle opération sur un fichier, il faut d’abord l’ouvrir. À cet effet, l’on utilise la fonction‘open()’. Pour ouvrie un fichier, l’on appliquera des arguments à la commande.
Les arguments les plus courants sont :
- ‘r’ : ouverture en lecture, le mode par défaut.
- ‘w’ : ouverture en écriture, il crée le fichier s’il n’existe pas.
- ‘a’ : ouverture en mode ajout, il écrit à la fin du fichier.
- ‘b’ : ouverture en mode binaire.
- ‘+’ : ouverture pour mise à jour, idéal pour lecture et écriture du fichier.
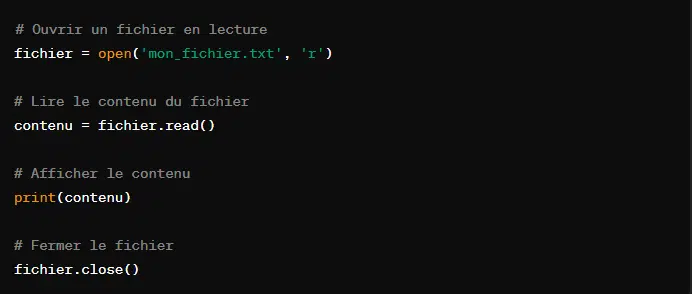
Voici un exemple pour illustrer l’ouverture d’un fichier avec la fonction ‘open()’ :
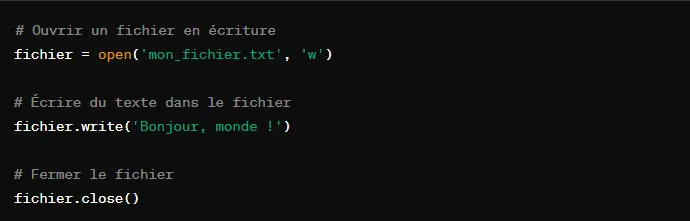
Voici comment écrire dans un fichier :
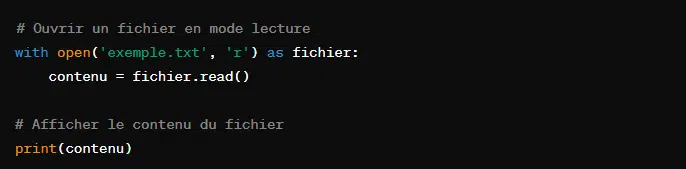
Cependant, il existe une manière plus efficace d’ouvrir et fermer automatiquement un fichier. Ainsi, même en cas d’erreur, le fichier est fermé et l’espace mémoire libéré. Pour cela, l’on se sert du gestionnaire de contexte ‘with’. Voici un exemple :

2. Lire le contenu intégral avec ‘read()’
En Python, la méthode ‘read’ est utilisée pour lire le contenu intégral d’un fichier ouvert. Lorsque l’on ouvre un fichier en mode lecture et en utilisant ‘read’ sans argument, la méthode retourne tout le contenu du fichier sous forme de caractères.
Toutefois, il faut éviter d’utiliser cette méthode avec des fichiers volumineux, car tout le contenu du fichier est chargé en mémoire. Dans de tels cas, il est plus recommandé de lire le fichier une ligne à la fois ou par blocs de taille définie.

3. Lire une ligne à la fois avec ‘readline()’
À chaque appel de la méthode ‘readline()’, elle lit une ligne du fichier et renvoie une chaîne de caractères. Une fois la fin du fichier atteinte, ‘readline()’ renvoie une chaîne vide (‘’).
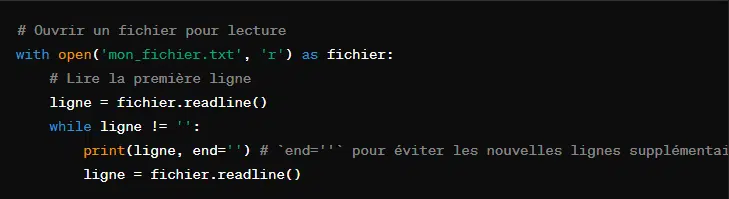
Voici un exemple d’utilisation de cette méthode :
4. Lire toutes les lignes avec ‘readlines()’
‘readlines()’ peut aussi être utilisée pour lire toutes les lignes d’un fichier. Elle renvoie ensuite le résultat sous forme de liste. Au sein de cette liste, chaque élément est une chaîne de caractères qui représente une ligne du fichier, y compris le caractère de fin de ligne (‘\n’).
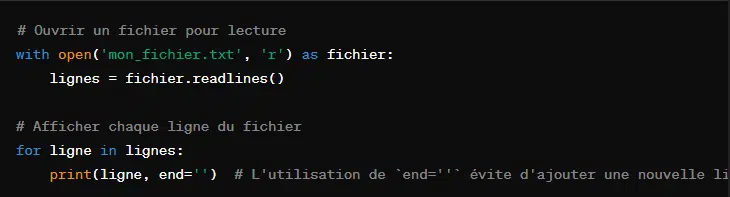
C’est une technique pratique pour lire un fichier et travailler sur chaque ligne du fichier.
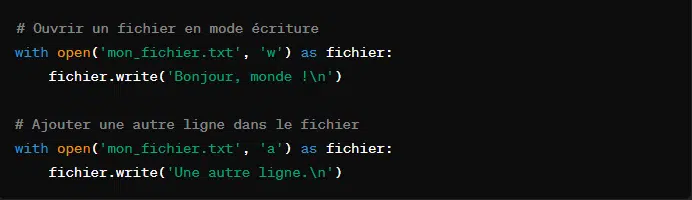
5. Écrire dans un fichier avec ‘write()’
Pour écrire une chaîne de caractères dans un fichier, l’on utilise la méthode ‘write’. Cependant, il faut faire attention aux arguments utilisés pour ouvrir le fichier.
Si le fichier est ouvert en mode écriture (‘w’), le contenu existant sera écrasé tandis que pour un fichier ouvert en mode ajout (‘a’), le nouveau contenu sera ajouté à la fin du fichier.
Par contre, pour écrire plusieurs lignes dans un fichier, l’on optera pour la méthode ‘writelines()’.
6. Écrire plusieurs lignes avec ‘writelines()’
Cette méthode prend une liste de chaîne de caractères et écrit chaque élement de cette liste dans le fichier. Mais, elle n’ajoute pas automatiquement de caractère de fin de ligne (‘\n’).
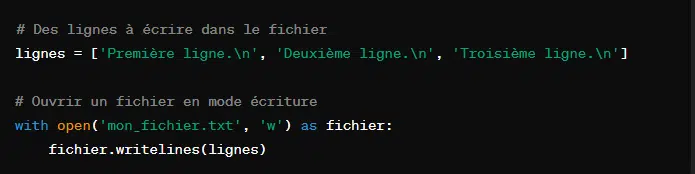
Puisque ‘writeline()’ n’ajoute pas de caractère de fin de ligne, il convient de les ajouter soi-même au besoin.
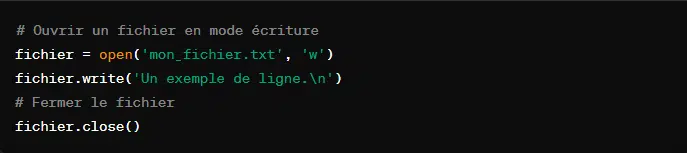
7. Fermer un fichier avec ‘close()’
Après avoir fini de travailler avec un fichier, l’on le ferme avec la fonction ‘close()’. Cette fonction permet de libérer l’espace mémoire occupé par le fichier. De plus, elle permet de bien sauvegarder les modifications apportées au fichier.
8. Utiliser‘with open()’ pour une gestion automatisée
Gérer manuellement l’ouverture et la fermeture d’un fichier peut conduire à des erreurs. Surtout si une exception est levée entre l’ouverture et la fermeture du fichier. Pour pallier cette situation, le mot clé ‘with’ vient à point nommé.
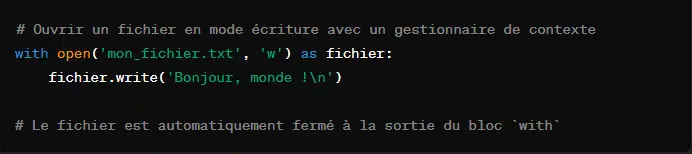
Le paramètre ‘with’ s’assurera que le fichier est bien fermé à la fin du bloc indenté. De plus, cete méthode garantit que les données sont bien sauvegardées.
9. Vérifier l’existence d’un fichier avec ‘os.path.exists()’
Avant d’ouvrir un fichier, l’on peut vérifier si celui-ci existe. Pour cela, l’on peut utiliser la fonction ‘os.path.exists()’. Elle retourne ‘True’ si le fichier existe dans le répertoire choisi et ‘False’ dans le cas contraire.
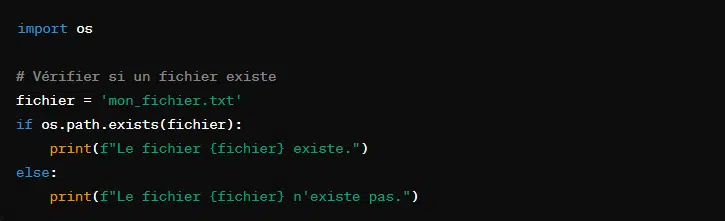
Cette fonction est utile pour éviter les erreurs à l’exécution lors de l’accès à des fichiers.
10. Supprimer un fichier avec ‘os.remove()’
Cette foncton supprime le fichier spcécifié par le chemin donné. Toutefois, avant de supprimerun fichier, il faut vérifier qu’il existe pour éviter les erreurs.
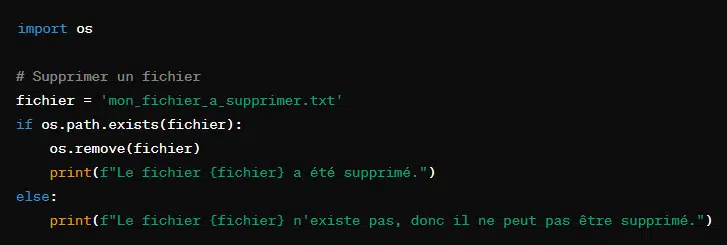
En outre, la suppression du fichier étant définitive, il faut être sûr de son action.
Interaction avec des API HTTP Simples
L’utilisation des API HTTP est indispensable dans le monde du développement logiciel. Elle permet aux applications de communiquer entre elles via le web. À cet effet, la bibliothèque ‘requests’ est utilisée pour effectuer presque toutes ces interactions.
1. Requête GET avec ‘requests.get()’
Cette requête est utilisée pour demander des données à une ressource spécifiée. De manière pratique, cela donne :
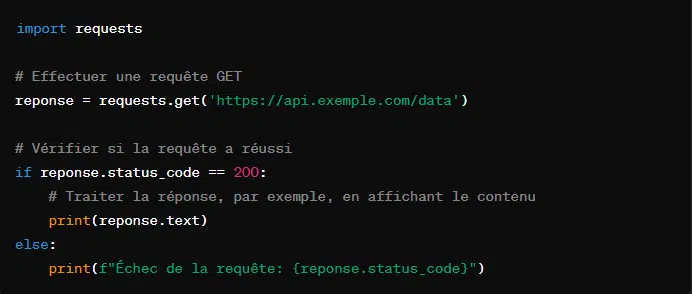
Il est à noter que pour des réponses JSON, l’on peut utiliser ‘reponse.json()’ pour les désérialiser automatiquement en un dictionnaire Python.
2. Requête POST avec ‘requests.post()’
Cette requête sert à envoyer des données à un serveur pour créer ou/et mettre à jour une ressource. Voici comment s’en servir :
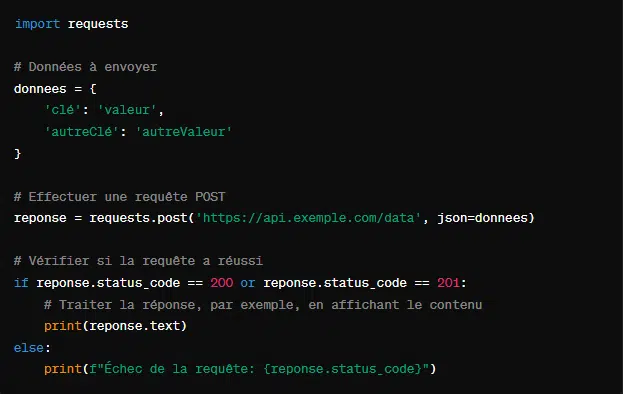
Il est à noter que la bibliothèque ‘requests’ s’occupe de la sérialisation des données en JSON et de la configuration de l’entête ‘Content-type’ appropriée.
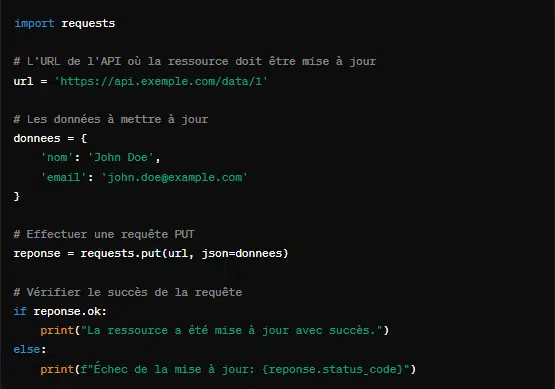
3. Requête PUT avec ‘requests.put()’
Contrairement à POST qui est utilisé pour créer une nouvelle ressource, PUT sert à mettre à jour ou remplacer une ressource existante. Cette requête est particulièrement utile pour les opérations de mise à jour où il est crucial que l’état de la ressource soit stable.
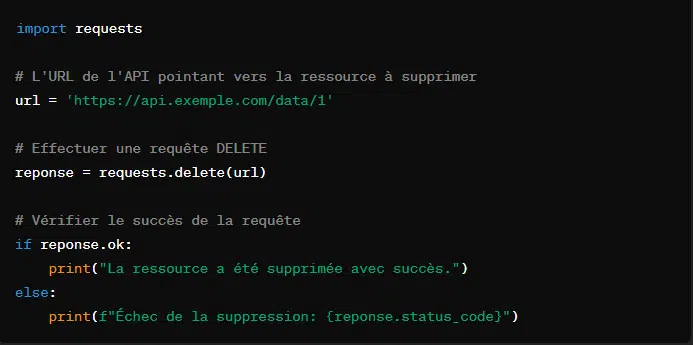
4. Requête DELETE avec ‘requests.delete()’
Cette requête est utilisée pour demander la suppression d’une ressource spécifiée. C’est le moyen le plus direct pour faire savoir à l’API ou au serveur web qu’il faut supprimer une ressource existant à l’URL fournie.
5. Requête HEAD avec ‘requests.head()’
Elle est similaire à la requête GET sauf que HEAD est principalement utilisée pour récupérer les en-têtes. Par exemple,
6. Requête OPTIONS avec ‘requests.options()’
Cette requête sert à décrire les options de communication pour une ressource cible. Le client se sert de cette méthode pour découvrir quelles méthodes HTTP et autres options sont supportés par le serveur.
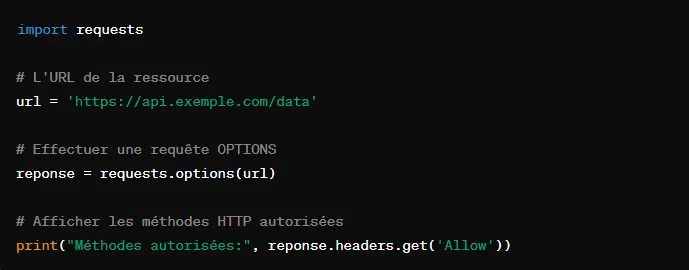
En plus de la récupération et de la soumission de données, la méthode ‘options’ permet de gérer le cycle de vie complet des ressources représentées.
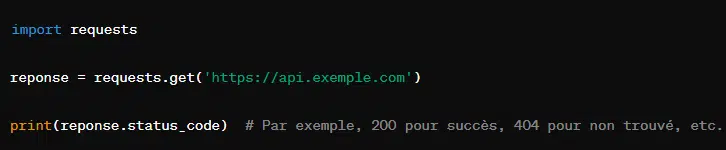
7. La requête STATUS CODE avec ‘response.status_code’
Cette requête contient le code de statut HTTP de la réponse du serveur. Le code de statut HTTP indique si une requête HTTP a été exécutée avec succès. Auquel cas, la requête STATUS CODE renvoie la raison de l’erreur.
8. La requête JSON avec ‘response.json()’
Quand le contenu de la réponse est du JSON, la requête du même nom décode le JSON en un objet Python. Cet objet Python peut être un dictionnaire ou une liste.
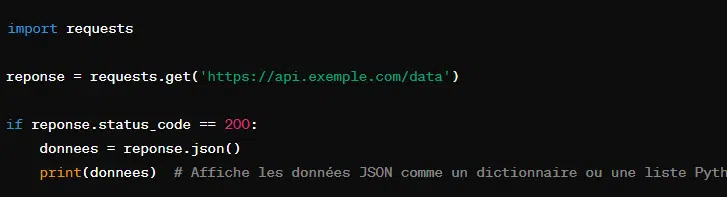
En outre, cette manoeuvre facilite l’accès et la manipulation des données retournées.
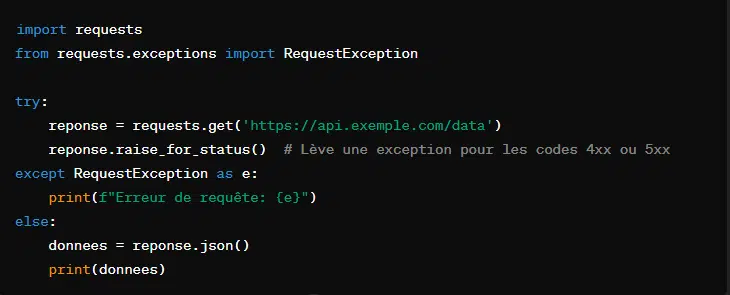
9. La requête EXCEPTION avec ‘requests.exceptions.RequestException’
Afin de gérer les erreurs survenues lors des requêtes HTTP, la bibliothèque ‘requests’ fournit plusieurs exceptions. À cet effet, la classe ‘RequestException’ existe pour gérer toutes ces exceptions émises par ‘requests’.
Manipulation de Listes et Dictionnaires
Les listes et les dictionnaires sont au cœur de la programmation en Python. Pouvoir les manipuler efficacement est une compétence indispensable pour tout développeur Python.
1. Ajout d’élément à une liste
Pour ajouter un seul élément à la fin d’une liste, l’on utilise la méthode ‘append()’. Cet élement peut être de n’importe quel type comme les nombres, les chaînes de caractères ou un liste. De plus, cet élement est ajouté tel quel, comme un unique élement.

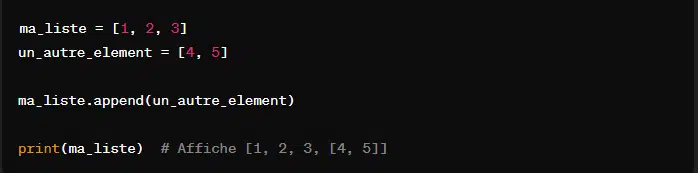
2. Extension d’une liste
Ici, l’on utilise ‘extend()’ pour combiner des éléments d’un itérable à la fin d’une liste existante. Cet itérable peut être une autre liste. Contrairement à ‘append()’ qui ajoute un seul élement à la fin d’une liste, ‘extend’ ajoute chacun des éléments séparement à la fin de la liste.
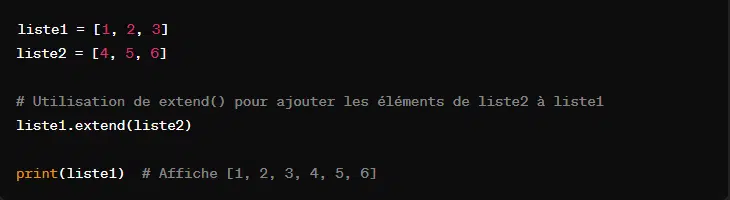
Comme énoncé précedemment, ‘extend()’ fonctionne avec n’importe quel itérable. Par exemple :
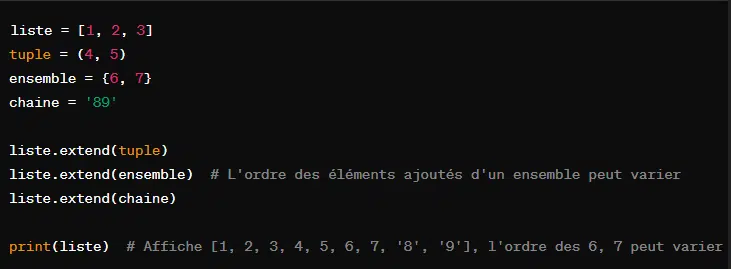
3. Slicing de liste
Le slicing de liste consiste en la récupération des sous-parties d’une liste en spécifiant le début, une fin et un pas. Cette technique peurt être utilisée aussi bien avec les listes qu’avec les chaînes de caractères, les tuples, etc. La syntaxe de base du slicing de liste est :

Cette technique admet quelques raccourcis dans sa syntaxe. Pour obtenir les x premiers éléments d’une liste, l’on peut juste omettre ‘debut’ et ‘fin’.

Pour obtenir les éléments avec un pas spécifique, il suffit d’omettre ‘debut’, ‘fin’ et mettre deux ‘:’:

En outre, l’on peut utiliser un pas négatif ou des indices négatifs pour respectivement inverser une liste ou pour compter à partir de la fin de la liste. De manière pratique, cela donne :


4. Compréhensions de liste
Cette fonctionnalité de Python permet de créer des listes de manière plus expressive et concise. La compréhension de liste offre un moyen de transformer, filtrer ou appliquer des opérations à des éléments provenant d’un itérable.
La syntaxe générale d’une compréhension de liste est :

De manière pratique, pour créer une liste de nombres carrés, par exemple, l’on a :

Cette fonctionnalité marche aussi pour les opérations complexes comme la conversion de température. L’on a :

5. Suppression d’éléments d’une liste
Python propose différentes manières de supprimer des éléments d’une liste. Chacune de ces manières ayant leurs cas d’usage et avantages. Les méthodes les plus courantes pour retirer les éléments d’une liste sont ‘remove()’, ‘pop()’ et l’opérateur ‘del()’.
D’abord, ‘remove()’ sert à supprimer la première occurrence de la liste qui correspond à la valeur spécifiée. Si cette occurrence n’existe pas, Python lève une exception ‘ValueError’.


Ensuite, ‘pop()’ supprime et renvoie un élément à un indice donné. Dans le cas où aucun indice n’est spécifié, il retire et renvoie le dernier élement de la liste.


Quant à l’opérateur ‘del()’, il sert à supprimer un ou plusieurs éléments d’une liste en spécifant leur indice. Il peut également être utilisé pour supprimer des tranches de la liste.


6. Trier une liste
En Python, il existe deux manières de trier une liste. D’une part, l’on peut modifier la liste originale en la triant grâce à la méthode ‘sort()’. Grâce à ‘sorted()’, l’on peut aussi créer une nouvelle liste triée qui laisse la liste originale échangée, d’autre part.
Voici un cas d’utilisation de la méthode ‘sort()’:

Pour tirer les éléments de la liste dans l’ordre décroissant, il suffit d’ajouter l’argument ‘reverse=true’ à la méthode ‘sort()’ :
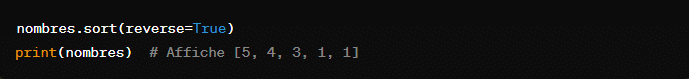
Quant à ‘sorted()’, il peut être utilsé pour trier n’importe quel itérable. Ce qui n’est pas le cas de ‘sort()’. De manière pratique, l’on a :

À l’instar de ‘sort()’, l’on peut trier une liste dans l’ordre décroissant en utilisant l’argument ‘reverse=true’ au sein de la méthode ‘sorted()’ :

7. Recherche dans une liste
Pour rechercher dans une liste, l’on a le choix entre la méthode ‘index()’ et l’opérateur ‘in’. ‘Index()’ est utilsé pour trouver l’indice spécifique d’un élément dans la liste tandis que ‘in’ permet de tester si un élément appartient à la liste.
La méthode ‘index()’ renvoie l’indice du premier élément de la liste qui est égal à la valeur spécifiée. Si l’élément n’est pas trouvé, Python lève une exception ‘ValueError’. Cela donne :
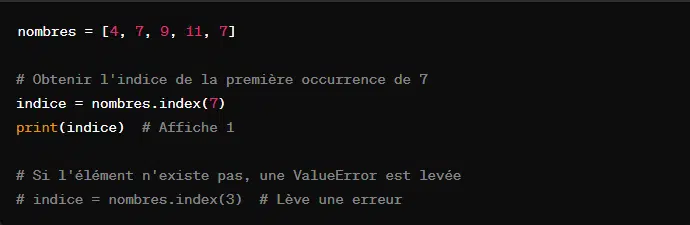
En outre, l’on peut également spécifier où commencer la recherche et où la finir.

Quant à l’argument ‘in’, il se contente de vérifier si l’élement appartient à la liste sélectionnée. Si c’est le cas, il renvoie ‘True’. Auquel cas, il renvoie ‘False’. Un cas pratique serait :
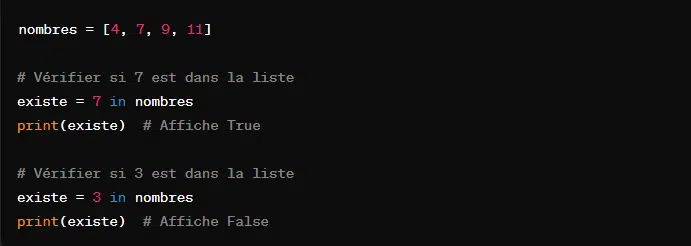
Cette technique de recherche est le plus souvent utilisée dans les boucles ou les conditions.
8. Opérations de dictionnaire
En Python, les dictionnaires sont des structures de données qui stockent des paires clé-valeur. Cela permet un accès à une valeur à partir de sa clé. Afin de simplifier les opérations sur les dictionaires, Python met à disposition les méthodes ‘get()’, ‘keys()’, ‘values()’, et ‘items()’.
D’abord, la méthode ‘get()’ permet d’accéder à la valeur associée à une clé donnée dans le dictionnaire.

Ensuite, la méthode ‘keys()’ renvoie un objet “Vue” qui contient toutes les clés du dictionnaire. Il est généralement utilisé dans les boucles for pour itérer sur toutes les clés du dictionnaire.

Quant à la méthode ‘values()’, elle renvoie également un objet “Vue”. Mais, celui-ci contient toutes les valeurs du dictionnaire.

Enfin, la méthode ‘items()’ est la plus puissante parmi celles destinées à l’accès et la manipulation des données au sein des dictionnaires. La méthode ‘items()’ renvoie une “Vue” qui contient des tuples pour chaque paire clé-valeur dans le dictionnaire.
Ainsi, il est possible d’itérer simultanément sur les valeurs et les clés.

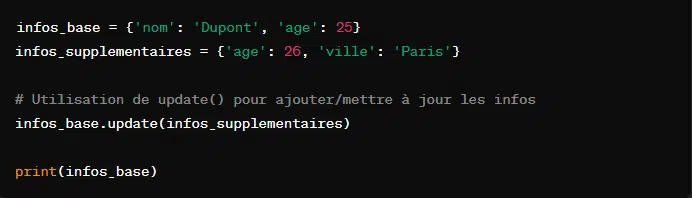
9. Mise à jour et fusion de dictionnaires
Pour mettre à jour et fusionner deux dictionnaires, l’on utilise la commande ‘update()’. Elle permet d’ajouter les paires clé-valeur d’un dictionnaire à un autre. Cette fonction est très utile pour mettre à jour un dictionnaire avec les valeurs d’un autre dictionnaire. Sa syntaxe de base est :

Pour fusionner deux dictionnaires, cela donne :
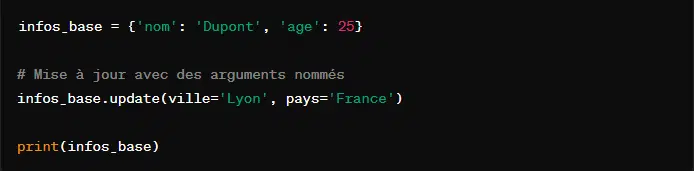
En outre, il est également possible d’utiliser des arguments nommés avec la méthode ‘update()’. Ils permettent d’ajouter directement des paires clé-valeur sans avoir besoin d’un autre dictionnaire.
En voici un exemple :
10. Compréhensions de dictionnaire
À l’instar des compréhensions de liste, la compréhension de dictionnaire est une fonctionnalité de Python qui permet de déclarer des dictionnaires de manière plus expressive et concise. Sa syntaxe de base est :

Quand on l’applique pour créer un dictionnaire à partir d’une liste, nous avons :

Il est également possible de se servir de la compréhension de dictionnaire pour filtrer les éléments d’un itérable. Pour cela, il suffit d’inclure une condition pour filtrer les éléments qui seront dans le nouveau dictionnaire.

Programmation Orientée Objet (POO)

La programmation orientée objet (POO) est un paradigme fondamental en programmation moderne. En Python, elle permet d’écrire un code modulaire, réutilisable et facile à maintenir.
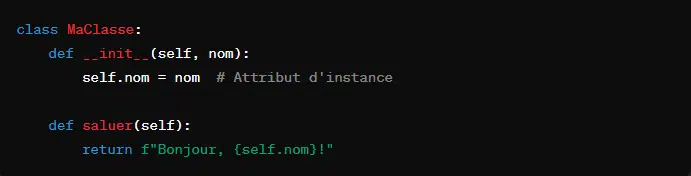
1. La définition de classe
La Programmation Orientée Objet repose sur la définition de classe. Une classe sert à créer des objets. Lesquels objets sont des instances de cette classe. En Python, chaque classe est définie grâce au mot-clé ‘class’ suivi du nom de la classe et d’un ‘:’.
2. L’instanciation d’objet
Ce processus implique la création d’une instance spécifique à partir d’une classe. Cette classe sert de modèle pour les objets. Celle-ci définit les attributs et les méthodes que les objets basés sur cette classe posséderont.
Pour instancier un objet en Python, l’on utilise le nom de la classe suivi de parenthèses.
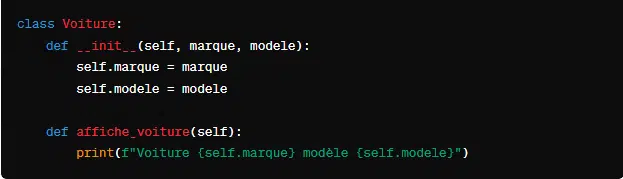

Ici, ma_voiture est une instance de la classe Voiture, créée avec la marque “Peugeot” et le modèle “208”. ma_voiture possède toutes les propriétés et méthodes définies dans Voiture, mais ses valeurs d’attributs sont propres à cette instance spécifique.
3. Les méthodes d’instance
Elles sont définies au sein d’une classe et destinées à opérer sur les instances de cette classe. En Python, pour définir une méthode d’instance, l’on utilise la référence ‘self’. Elle permet d’accéder aux attributs et méthodes de l’instance. De manière pratique, nous avons :
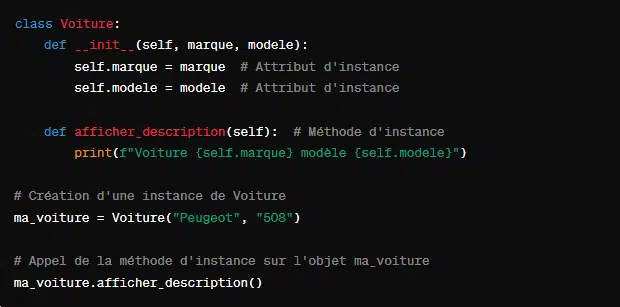
Ici, ‘self’ est utilisé pour accéder aux attributs marque et modele de l’instance spécifique sur laquelle la méthode est appelée.
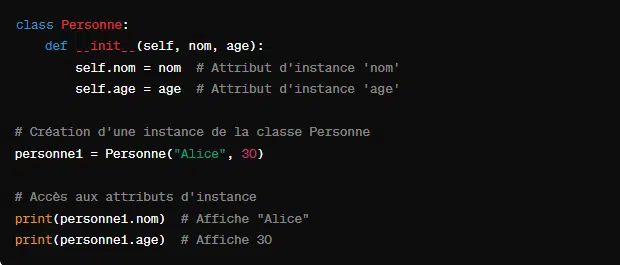
4. Les attributs d’instance
Les attricuts d’instance sont des variables liées à des instances spécifiques d’une classe. Elle permet de distinguer chaque objet d’une classe par ses propres valeurs d’attributs. On définit un attribut d’instance en utilisant le constructeur de classe ‘__init__’.
Voici un exemple :
5. Le constructeur ‘__init__’
Ce constructeur spécial de classe sert à initialiser de nouvelles instances d’une classe prédéfinie. Loesqu’un objet est créé, la méthode ‘__init__’ est appelée avec l’objet lui-même comme premier argument. Cet objet est généralement nommé ‘self’.
Voici comment initialiser les attributs d’une classe Personne réprésentant une personne avec un nom et un âge :
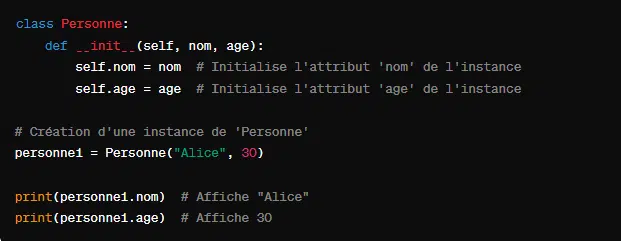
Une fois la nouvelle instance Personne créée avec Personne(“Alice”, 30), la méthode ‘__init__’ est appelée. Suite à quoi, “Alice” et 30 sont passés comme argument à ‘__init__’. Ce dernier initialise ensuite les attirbuts “nom” et “age” de l’instance “personne1”
6. L’héritage
L’héritage est un des piliers de la Programmation Orientée Objet. Elle permet à une classe fille ou sous-classe d’hériter des attributs et méthodes d’une autre classe dite parente ou super-classe.
Ce concept permet d’ordonner et structurer le code de manière hiérachique. Tout cela contribue à une meilleure maintenabilité du code. La syntaxe de base de l’héritage en Python est la suivante :

Soit une classe Vehicule qui repésente des véhicules de manière générale. L’on peut définir des classes Voiture ou Moto qui hériteront de Vehicule pour spécifier des types de véhicules plus précis. Cela donne :
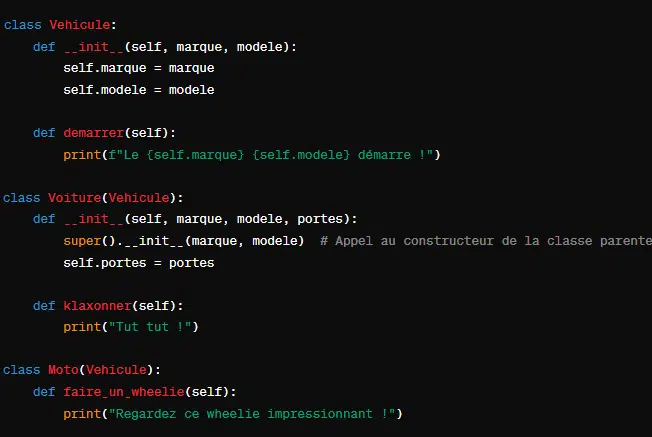
Ici, les classes Voiture et Moto ont accès à des méthodes comme ‘demarrer()’. Dans ce cas de figure, l’ajout de la méthode ‘super().‘__init__’(marque, modele) appelle la classe parente et initialise les attributs hérités.
Ainsi, chaque sous-classe peut ajouter ses méthodes spécifiques comme ‘klaxonner’ pour Voiture et ‘faire_un_wheelie’ pour Moto.
7. Les méthodes de classe et les méthodes classiques
Ce sont deux types spéciaux de méthodes qui ont des utilisations et des comportements distincts par rapport aux méthodes habituelles d’instance. Ces méthodes sont définies au sein d’une classe. Mais, elles sont conçues pour ne pas agir sur des instances spécifiques de cette classe.
Une méthode de classe est définie par @classmethod tandis qu’une méthode de classe se définit par @staticmethod.
La méthode de classe reçoit la classe elle-même comme premier argument plutôt qu’une instance de cette classe. Voici comment la définir :
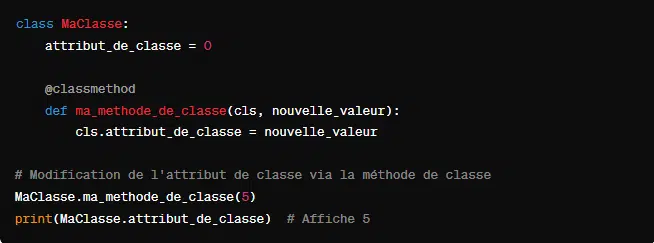
Quant à la méthode statique, elle ne reçoit ni l’instance ni la classe comme premier argument. Elle ne peut donc pas accéder ou modifier l’état de la classe ou de l’instance. De manière pratique, voici comment définir une méthode statique :
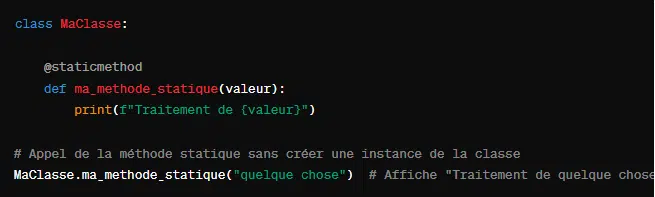
8. L’encapsulation
En Python, l’encapsulation est une technique qui sertà restreindre l’accès aux composantes internes d’une classe. L’on peut ainsi cacher les détails de l’implémentation d’une classe et n’exposer aux utilisateurs que ce qui leur est nécessaire.
Pour encapsuler un objet en Python, il existe deux conventions :
- L’attribut protégé. Il suffit de préfixer un attribut d’un seul underscore (‘_’). Cela implique que cet attribut ne devrait pas être accédé en dehors de la classe et des sous-classes liés ;
- L’attribut privé. Ici, il faut pefixer un attribut non pas d’un mais de deux underscores (‘__’). Cette manoeuvre rend cet attribut plus difficile d’accès en dehors de la classe.
De manière pratique, voici un exemple d’encapsulation en Python :
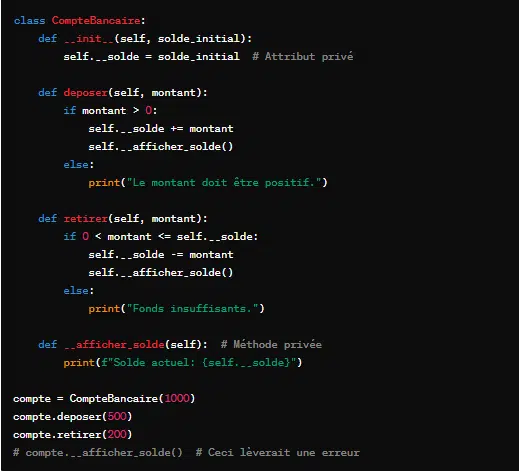
Ici, le solde du compte est un attribut privé (__solde), ce qui signifie qu’il ne peut pas être accédé directement depuis une instance de la classe. De même, la méthode __afficher_solde() est privée et ne peut être appelée que de l’intérieur d’autres méthodes de la classe CompteBancaire.
9. Le polymorphisme
Ce concept clé en POO permet aux objets de différents types d’être traités à travers une même interface. Cette technique permet de concevoir des fonctions ou des méthodes génériques qui peuvent opérer sur des objets de différents types.
Soit une fonction qui appelle la méthode ‘parler()’ sur un objet passé en argument. Les objets de classes différentes peuvent avoir leur propre impléenation de ‘parler’. Mais, la fonction qui les appelle reste la même. En voici un exemple :
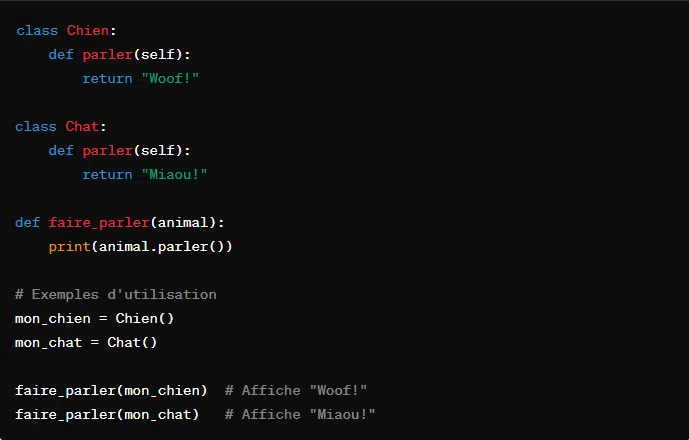
Ici, bien que les classes Chien et Chat soient différentes, elles peuvent êtres utilisées par la fonction ‘faire_parler’ grâce au polymorphisme.
10. Les méthodes spéciales
Encore appelées les méthodes magiques, les méthodes spéciales sont des fonctions prdéfinies par Python. Elles permettent de personnaliser le comportement des classes. Ces méthodes sont invoquées par Python pour réaliser différentes opérations.
Parmi ces méthodes spéciales, l’on compte :
- ‘__init__(self, …)’. Elle est appelée automatiquement lorsqu’un nouvel objet est créé à partir d’une classe et sert à initialiser les attributs de l’objet ;

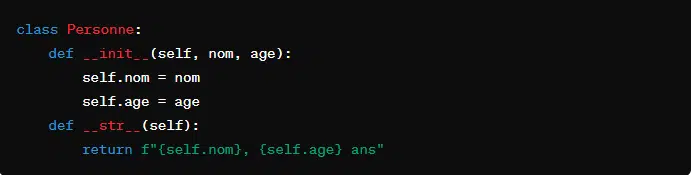
- ‘__str__(self)’. Elle définit la représentation en chaîne de caractères “informelle” ou “lisible” d’un objet.
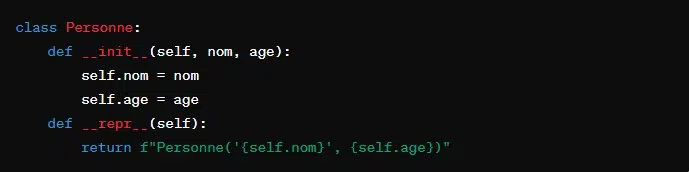
- ‘__repr__(self)’. Cette méthode spéciale définit la représentation officielle d’un objet. Elle est utilisée par la console Python pour afficher l’objet.
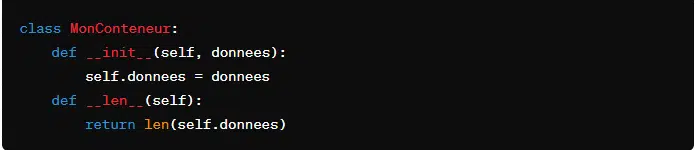
- ‘__len__(self)’. Elle renvoie la longueur de l’objet.
L’utilisation de bibliothèques utiles
Pour quasiment toutes les opérations effectuées en Python, l’on doit faire appel à une bibliothèque. Cette dernière contient des modules et packages qui fournissent des fonctons pré-écrites et des méthodes pour effectuer une tâche précise.
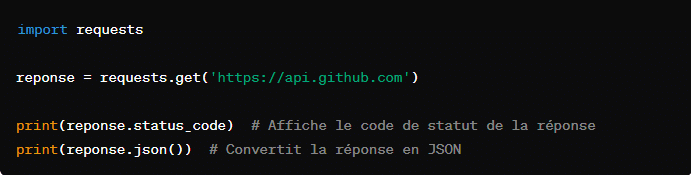
1. Requests
Cette bibliothèque est conçue pour simplifier l’envoi de requêtes HTTP. Contrairement au module ‘urlib’, Request offre une interface plus intuitive et facile à utiliser pour les développeurs.
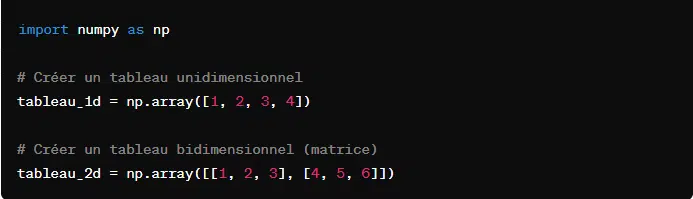
2. NumPy
Numpy permet de travailler avec des tableaux et matrices. Elle permet de réaliser des opérations mathématiques complexes de manière efficace sur ces structures de données. Voici quelques exemples pratiques :
- Pour créer un tableau :
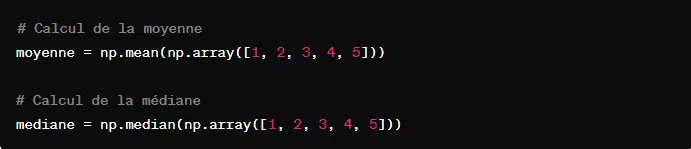
- Pour des fonctions mathématiques de niveau :
- Pour manipuler les tableaux :

3. Pandas
Pandas est construit sur la bibliothèque NumPy. Il rend l’analyse de données rapide, facile et expressive. Il fournit des structures de données flexibles et intuitives conçues pour travailler flexiblement avec des données structurées.
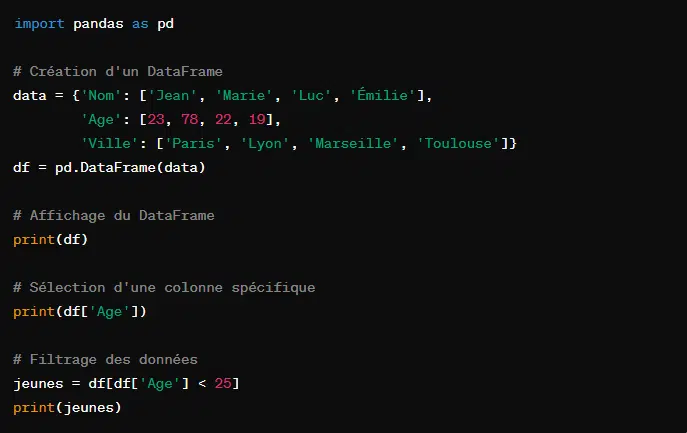
4. Matplotlib
C’est une bibliothèque de visualisation de données en Python. Elle permet de créer des graphiques et des figures. Avec Matplotlib, l’on peut générer des graphiques linéaires, des graphiques à dispersion, des diagrammes circulaires et plus encore.
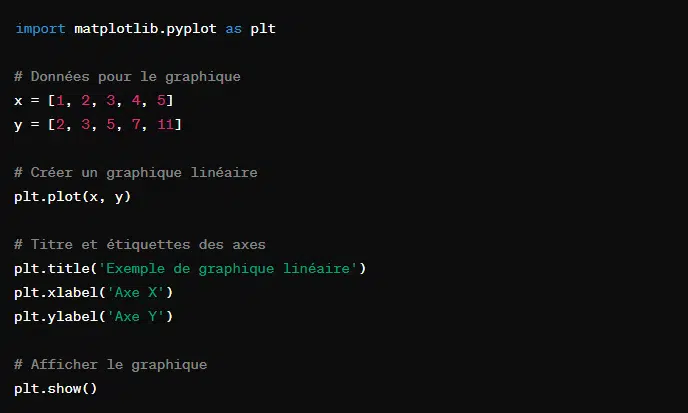
Ici, l’on crée un graphique simple où x et y sont les données sur les axes. La fonction plt.plot(x, y) crée le graphique linéaire, plt.title(), plt.xlabel(), et plt.ylabel() ajoutent un titre au graphique et des étiquettes aux axes. Enfin, plt.show() affiche le graphique à l’écran.
5. Scikit-learn
Cette bibliothèque Python est dédiée au machine learning. Elle propose divers outils pour préparer ses données pour l’apprentissage automatique. Elle sert aussi à construire, évaluer et déployer des modèles.
Scikit-Learn est compatible avec les bibliothèques NumPy et Pandas. Cela facilite la manipulation des données et l’intégration dans des pipelines pour la data science.
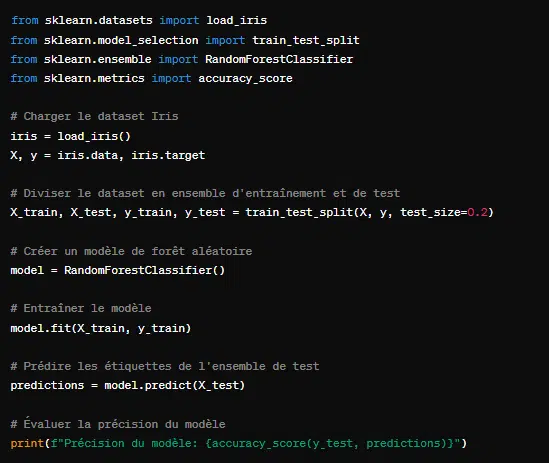
Ici, grâce à Scikit-learn, l’on arrive facilement à charger des données, de les diviser en ensembles d’entraînement et de test, de choisir un modèle, de l’entraîner et de l’évaluer.
6. Beautiful Soup
Beautiful Soup est une bibliothèque qui facilite l’extraction d’informations à partir de pages web. Pour cela, elle convertit les documents HTML ou XML en objets Python navigables. Elle est très utilisée pour le web scraping.
Voici comment extraire tous les liens d’une page web grâce à Beautiful Soup :
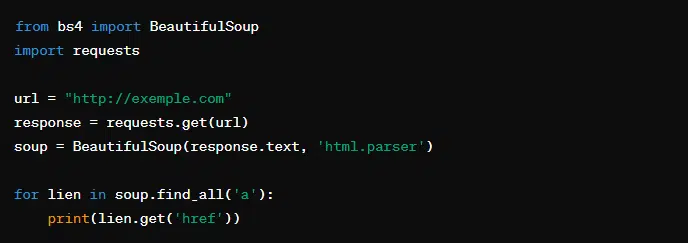
Dans cet exemple, ‘requests.get(url)’ est utilisé pour récupérer le contenu de la page. ‘BeautifulSoup(response.text, ‘html.parser’)’ parse ce contenu en un objet ‘soup’, à partir duquel l’on peut extraire des informations spécifiques, comme tous les éléments (liens).
7. Flask
Flask est conçue pour le développement d’applicatons web. Sa simplicité et sa flexibilité font de Flask une bibliothèque de premier choix pour les développeurs désireux de créer des sites web et des API.
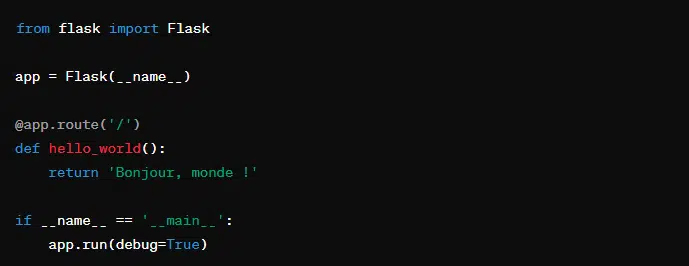
Ce bout de code crée une application web qui dit “Bonjour, monde !” lorsqu’elle est excutée à l’adresse racine (‘/’). En outre, Flask prend en charge le rechargement automatique pendant le devéloppement et permet de tester rapidement les modifications.
8. Django
Tout comme Flask, Django est un framework Python de développement web. Il aide à construire des applications web rapidement et avec moins de code.
En effet, Django vient avec une variété de fonctionnalités comme l’authentification des utilisateurs, des formulaires ou une interface d’administration. Voici un exemple simple de création d’une projet Django :
- Installer Django.

- Créer un projet Django.

- Lancer le serveur de développement.

Enfin, il suffit d’accéder à son projet Django en naviguant vers ‘http://127.0.0.1:8000/’ dans son navigateur web.
9. TensorFlow
C’est une bibliothèque de programmation puissante dédiée au calcul numérique. Elle est largement utilisée pour la recherche et production dans le domaine du machine learning et du deep learning.
Elle permet de construire et de former des réseaux de neurones pour détecter et décrypter des schémas et des corrélations similaires à la manière dont les humains apprenent.
Voici comment utiliser TensorFlow pour effectuer une régression linéaire :
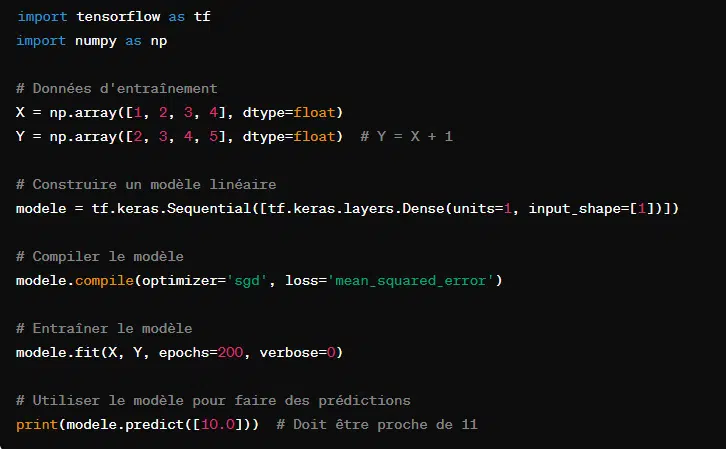
10. PyTorch
Pytorch est une bibliothèque open-source de machine learning. Elle offre deux fonctionnalités principales.
D’une part, elle permet de faire des calculs numériques accélérés grâce à l’utilisation des processeurs graphiques. Elle fournit une plateforme pour la recherche et le développement en deep learning, d’autre part.
PyTorch repose sur les Tensors, l’équivalent des arrays de NumPy. La différence notable étant que les Tensors sont boostés par la puissance des GPU.
A titre d’exemple, voici comment créer un réseau de neurones avec PyTorch, faire l’initiation d’un modèle, la définition d’une fonction de perte et l’optimiseur, et une itération d’entraînement.
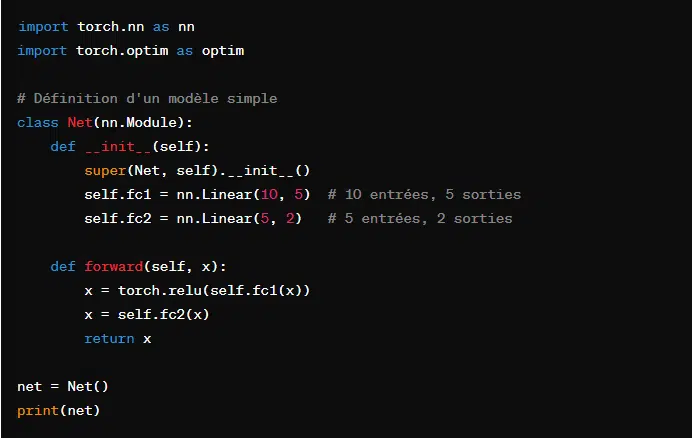
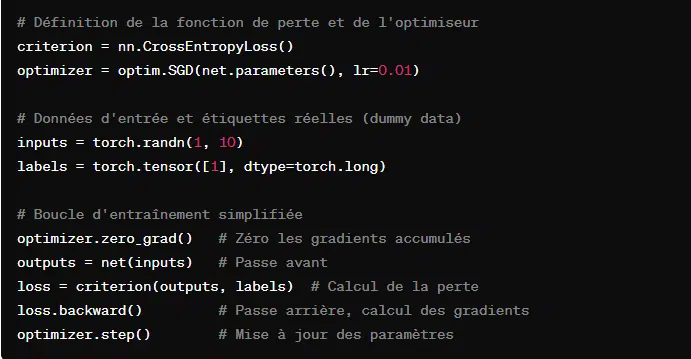
Le scripting et l’automatisation
Cette section montre comment exécuter des commandes système, planifier des tâches, parser des arguments et interagir avec des navigateurs web.
1. Exécution de commandes shell
Grâde à la bibliothèque ‘subprocess’, il est possible d’exécuter des commandes shell et des scripts depuis son code Python. Elle sert à lancer des processus externes ou obtenir des résultats de sortie. Voici quelques cas d’utilisation de ‘subprocess’ :
- Exécuter une commande simple :
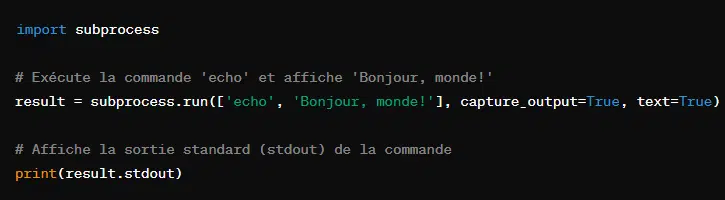
- Capturer l’erreur :
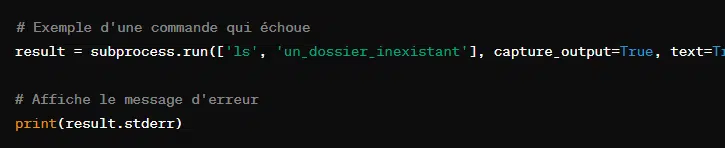
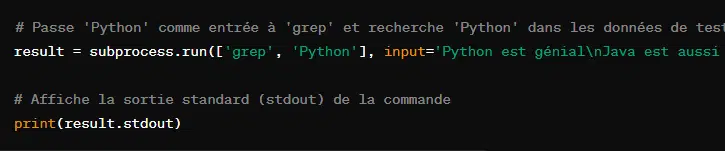
- Passer des entrées à un processus :
2. Manipulation de fichiers et de dossiers
Le module ‘os’ met à disposition des développeurs une pléthore de fonctions pour manipuler les fichiers et dossiers. Il est donc plus aisé d’effectuer des opérations courantes sur les systèmes de fichiers.
Par exemple, pour charger le répertoire de travail :
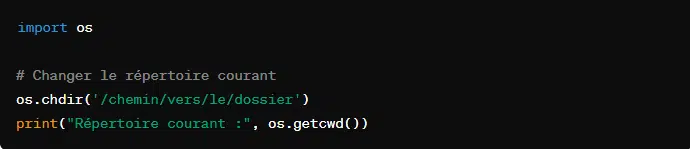
Pour lister les fichiers et dossiers :

En outre, pour supprimer un dossier ou un fichier :


3. Planification de tâches
Python offre plusieurs moyens pour planifier l’exécution de code grâce aux modules ‘sched’ et ‘schedule’.
‘Sched’ est un planificateur d’évènements basé sur le temps. Son approche est basée sur la gestion explicite des événements et des délais pour exécuter des tâches.
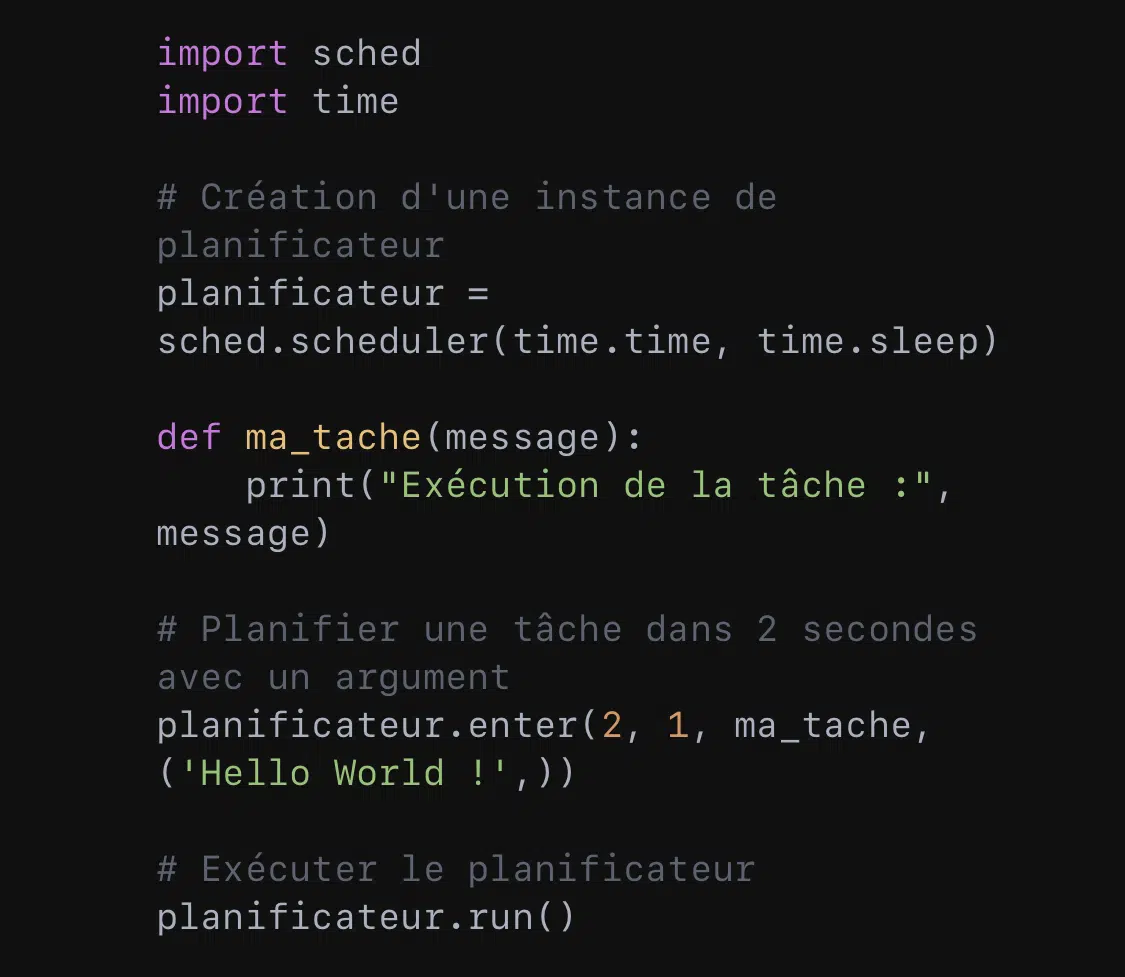
Ici, ‘ma_tache’ est planifiée pour s’exécuter une fois après un délai de deux secondes. Le deuxième argument de enter est une priorité, où des nombres plus petits indiquent une priorité plus élevée si plusieurs événements sont planifiés en même temps.
Quant au module ‘schedule’, il a une bibliothèque tierce qui permet une syntaxe plus simple et intuitive pour planifier l’exécution de tâches.
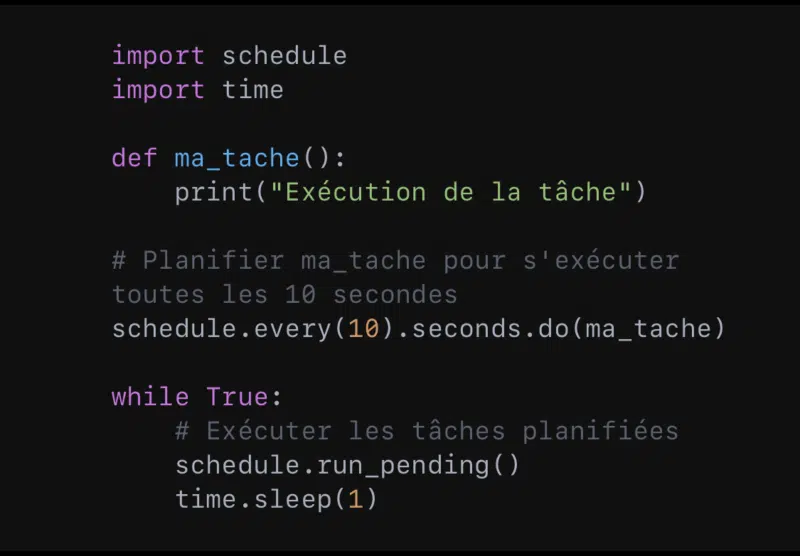
Avec ‘schedule’, l’on peut planifier des tâches récurrentes à des intervalles spécifiques.
4. Parsing d’arguments de ligne de commande
Pour parser des arguments de ligne de commande, l’on se sert du module ‘argparse’. C’est un outil puissant de Python pour créer des interfaces utilisateur en ligne de commande.
Voici un exemple de script qui a besoin de deux entrées de l’utilisateur. L’un, obligatoire, est le nom et l’autre, optionnel, est le niveau de verbosité.
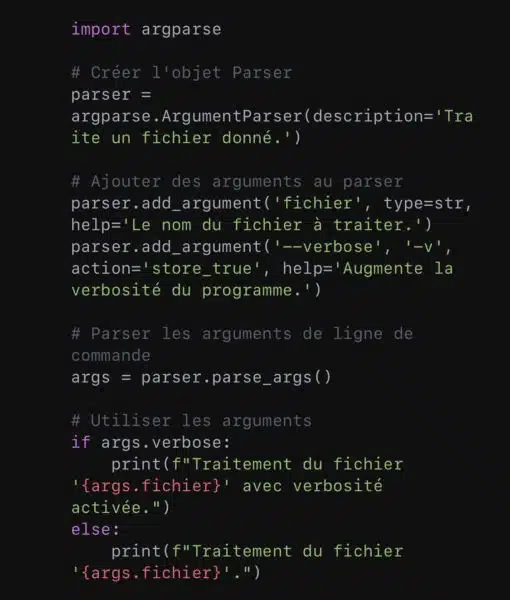
Dans cet exemple, fichier est un argument positionnel, ce qui signifie que l’utilisateur doit le fournir pour que le script s’exécute. L’argument –verbose (qui peut aussi être abrégé en -v grâce à l’option action=’store_true’) est optionnel et sert à contrôler le niveau de verbosité du script.
Il convient de préciser que la verbosité, ici, représente le niveau de détail des informations que le programme fournit à l’exécution.
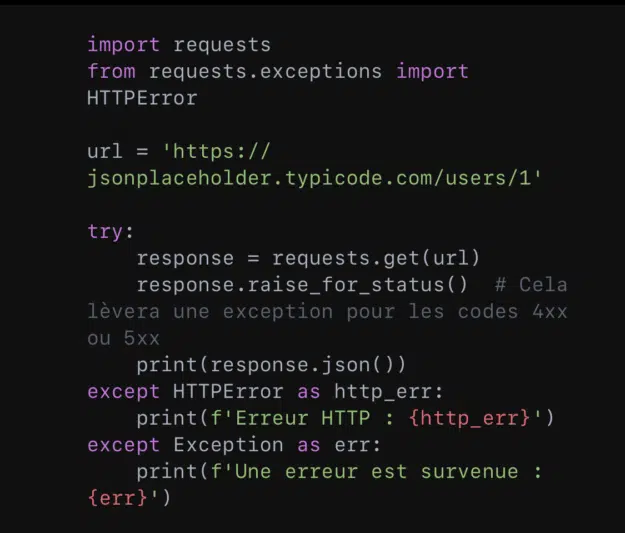
5. Les interactions avec des API web
La bibliothèque ‘requests’ permet d’envoyer des requêtes HTTP de manière intuitive et de traiter les réponses reçues. Toutefois, il est important de gérer les exceptions. L’on s’assure ainsi que son script peut gérer les cas où une requête échoue.
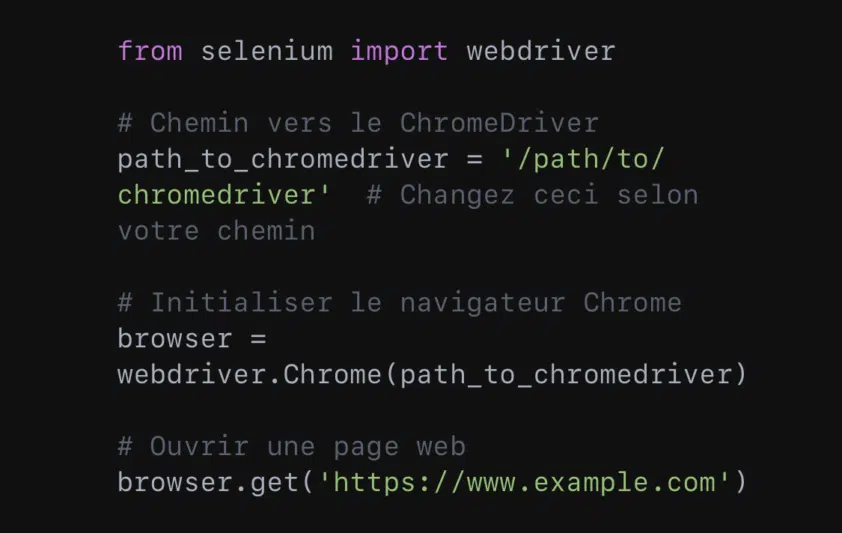
6. Automatisation des navigateurs web
Selenium est une bibliothèque Python qui permet d’automatiser les navigateurs web pour effectuer des tâches. Ces tâches vont du test d’applications web au scraping de données web en passant par l’automatisation de tâches répétitives.
Par exemple, pour ouvrir une page web, l’on fait :
7. Gestion des expressions régulières
Encore appelées regex, les expressions régulières sont un outil puissant pour la recherche et la manipulation de texte. Grâce au regex, l’on peut spécifier des motifs de châine de caractères complexes à rechercher, remplacer ou manipuler dans un texte.
À cet effet, Python met à disposition le module ‘re’. Ce dernier fournit des fonctions pour travailler avec des expressions régulières. Ainsi, l’on peut :
- Rechercher une correspondance :
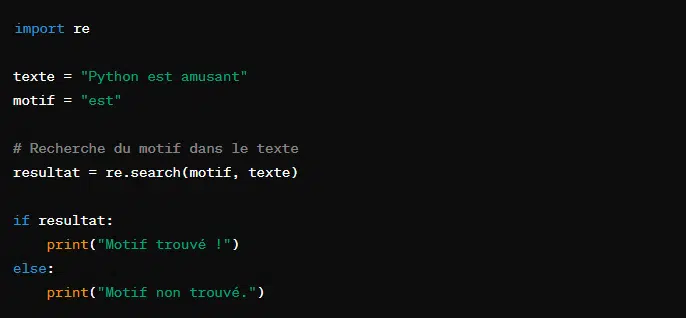
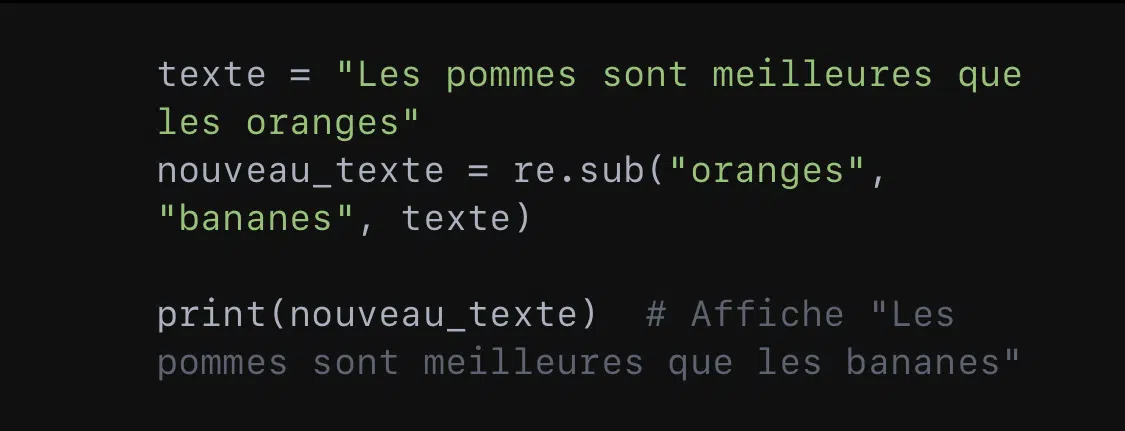
- Remplacer du texte :
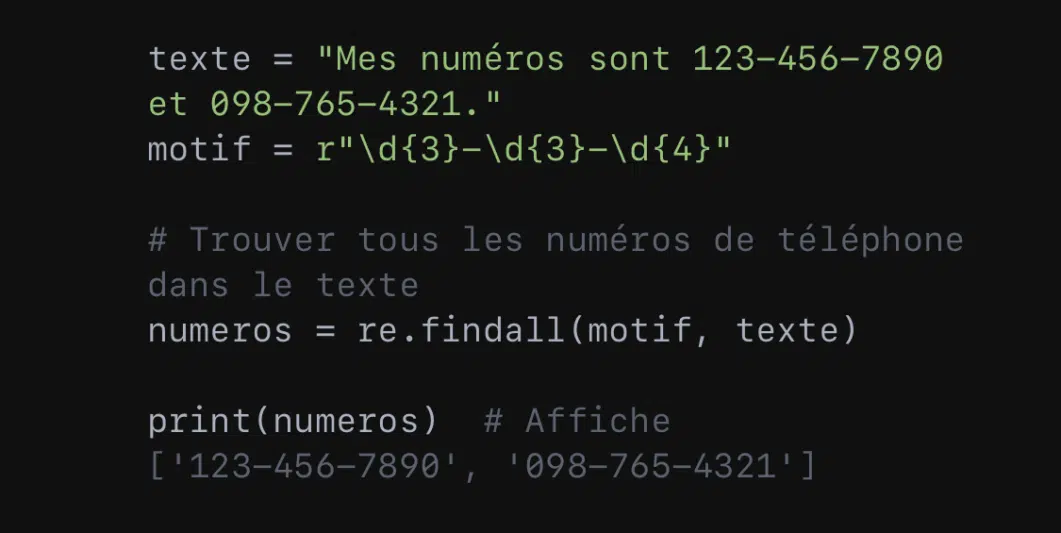
- Extraire des informations :
8. Travail avec des données JSON
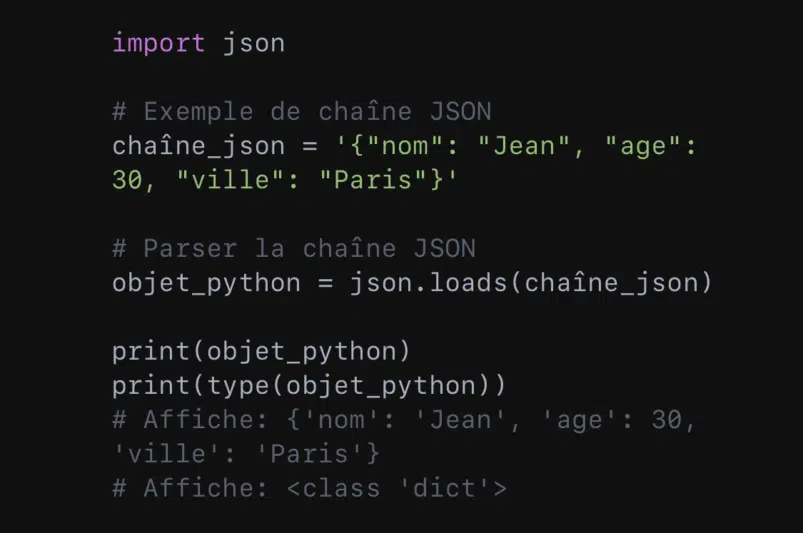
Quand l’on a affaire à des données au format JSON, le module ‘json’ est le choix le plus adapté pour travailler avec ses données. Voici comment utiliser le module ‘json’ pour décoder et générer des données JSON en Python :
- Pour convertir une chaîne JSON en un objet Python, il faut utiliser la méthode ‘json.loads()’ :
- Pour convertir un objet Python en une chaîne JSON, l’on se sert de la méthode ‘json.dumps()’ :
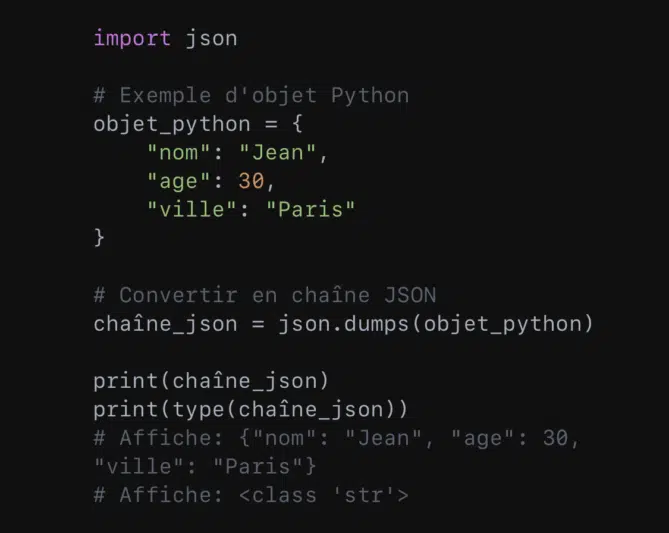
9. Gestion des environnements virtuels
En Python, les environnements virtuels sont cruciaux. En effet, ils permettent d’isoler un projet avec ses propres dépendances et bibliothèques spécifiques. Le but étant de faciliter la portabilité des scripts en définissant leurs dépendances.
Le module par excellence pour cette tâche est ‘venv’. Voici comment s’en servir pour :
- Créer un environnement virtuel :

- Activer et désactiver l’environnement virtuel :


- Installer des paquets dans l’environnement virtuel :

10. Le logging
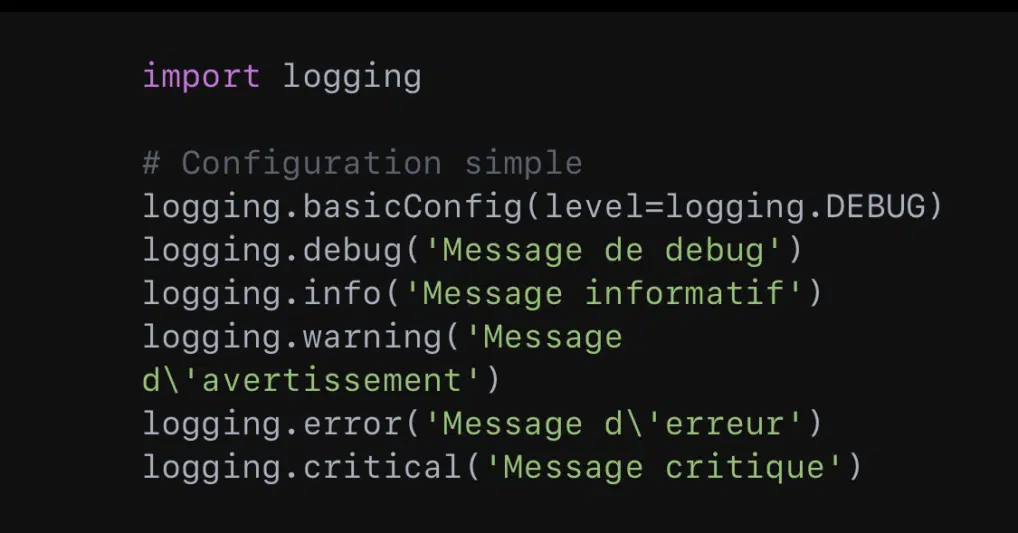
Pour suivre les événements, diagnostiquer les problèmes et garder une trace des opérations effectuées par le script, l’on utilise le module ‘logging’. C’est un système flexible de journalisation adapté aux cas d’usage basiques.
Avant de loggger des messages, il faut configurer le système de logging. Pour cela, l’on se sert de la fonction ´logging.basicConfig()’ :
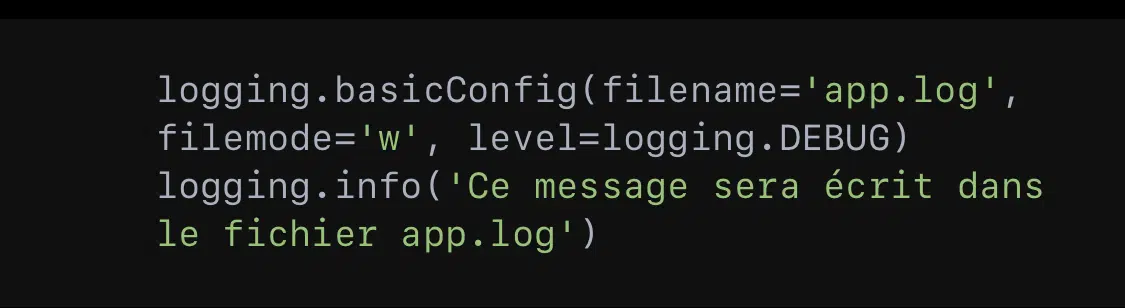
Pour enregistrer les logs dans un fichier plutôt que de les afficher sur la console, il faut spécifier le nom du fichier lors de la configuration :
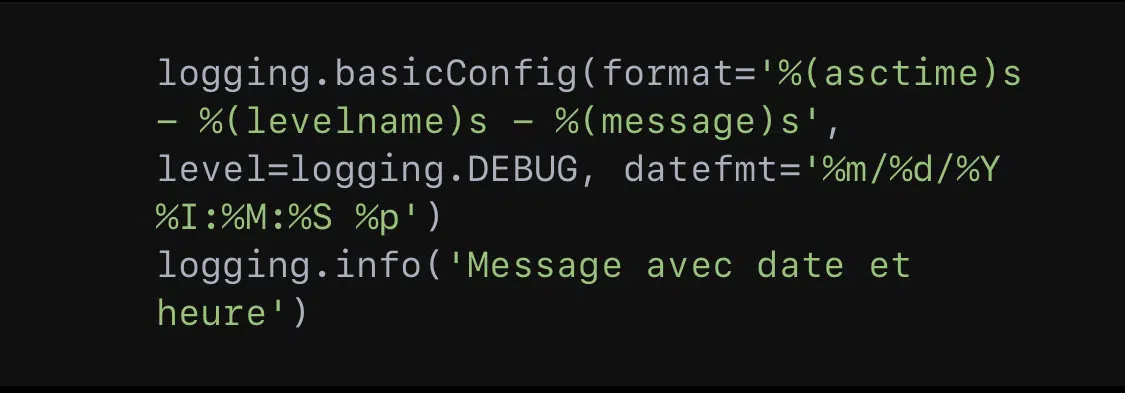
En outre, l’on peut également personnaliser le format des messages de log. L’on a :
Conclusion
Que vous soyez un développeur Python débutant ou confirmé, cet aide-mémoire ultime est un outil puissant à avoir dans votre boîte à outils.
Des opérations sur les fichiers à la programmation orientée objet, en passant par l’utilisation des bibliothèques populaires et l’automatisation, vous disposez désormais d’une ressource complète pour booster votre productivité en Python.
 Les concepts clés en JavaScript pour les développeurs seniors
Les concepts clés en JavaScript pour les développeurs seniors
Leave a Reply