
L’administration et la recherche d’informations au sein d’énormes bases de données est aujourd’hui plus simple grâce à Elasticsearch. Utilisé par Microsoft, Facebook ou encore Netflix, Elasticsearch s’est rapidement imposé comme étant ‘LA’ solution pour stocker et gérer des bases de données.
Il est donc logique de se demander quelles sont les utilisations possibles d’une telle technologie. Cet article en parle justement. En plus de vous informer sur les concepts liés à ce moteur de recherche, il vous renseignera sur les fonctions d’Elastic Search.
Elasticsearch, qu’est-ce que c’est ?
Lancé en 2010, ElasticSearch est un moteur de recherche et d’analyse de données en open source, distribué et basé sur la bibliothèque Apache Lucene. Il permet de stocker, de rechercher et d’analyser de larges volumes de données rapidement et en quasi-temps réel (NRT).
Cet outil possède des caractéristiques particulièrement intéressantes. Par exemple, il emmagasine les données en format JSON et annule de ce fait le besoin d’associer à son application de recherche un support de stockage.
Sa structure est donc basée sur des documents JSON plutôt que sur des tableaux et des schémas. Associée aux fonctionnalités d’indexation et de recherche de contenu sur ces documents d’Apache Lucene, elle permet à Elasticsearch de fournir des résultats en à peine quelques millisecondes !
Ce n’est pas tout, Elasticsearch :
- Traite aussi bien les données structurées et non structurées ;
- S’appuie sur Logstash, un logiciel de gestion de logs et Kibana, une plateforme d’exploration et de visualisation des données ;
- Offre des analyses pertinentes, puissantes et scalables, même avec des mots-clés peu précis ;
- Dispose de REST API qui lui permettent de s’interroger et d’explorer les données.
Toutes ces capacités, qui ne sont d’ailleurs qu’un aperçu des applications d’Elasticsearch, expliquent pourquoi il est parmi les outils de recherche les plus réputés, devant Apache Solr.
Les concepts essentiels liés à l’Elasticsearch
Pour mieux apprécier les capacités offertes par Elasticsearch, il faut que vous compreniez l’ensemble des concepts clés mis en œuvre par ce moteur et la relation qui lie ces concepts entre eux. Voici un bref exposé sur ces concepts.
Le near real-time (NRT)
En informatique, le near real-time ou quasi temps-réel désigne le léger délai (généralement 1 seconde) entre le moment où un document est indexé et celui où il est accessible à la recherche.
Le nœud
Le nœud est un processus applicatif dans un serveur capable de s’exécuter indépendamment. Son rôle consiste à stocker des données et à offrir des capacités d’indexation et de recherche. Il est désigné par un nom unique servant à l’identifier.
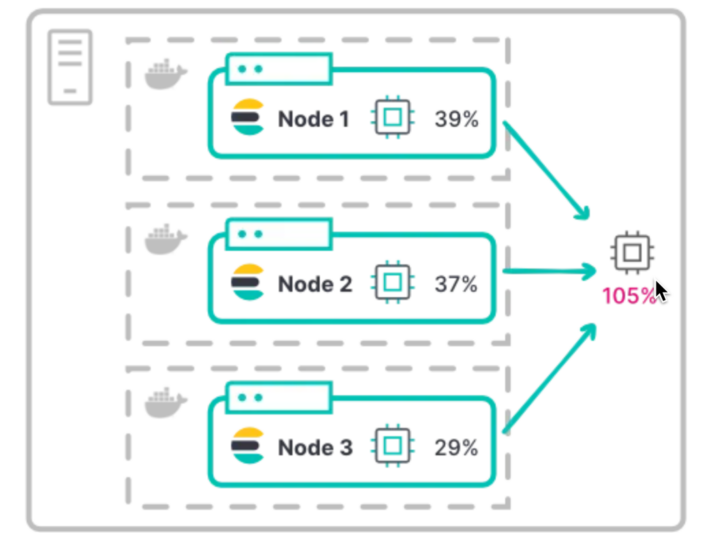
Crédit de l’image : Ryan Eno
Le cluster
Le cluster sur Elasticsearch est un ensemble constitué par un ou plusieurs nœuds ayant une caractéristique commune. Ceux-ci contiennent conjointement l’intégralité de vos données et fournissent des fonctionnalités d’indexation et de recherche.
Sa fonction est de fournir l’indexation collective et la distribution des requêtes à travers tous les nœuds du cluster.
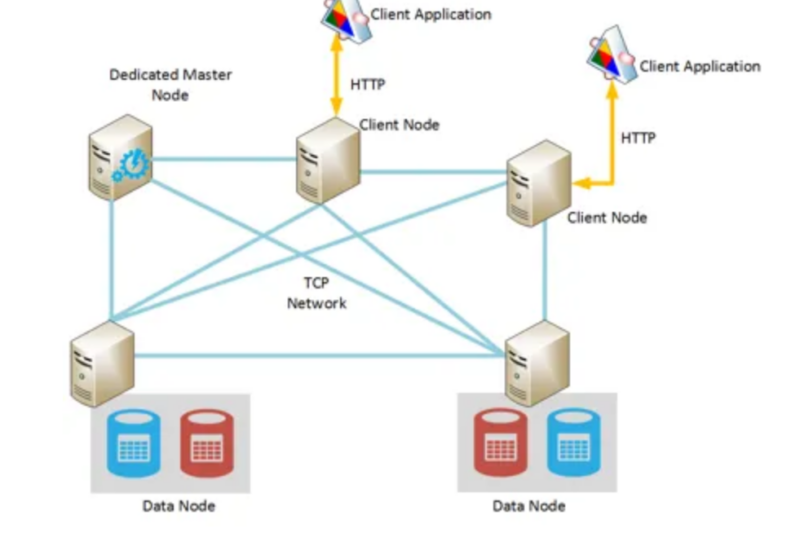
Crédit de l’image : K Hong
L’index
Dans la terminologie d’Elasticsearch, un index est un ensemble de documents JSON identifié par un nom en lettres minuscules.
Reposant sur le mécanisme de fragmentation, les index permettent au système de gestion de données de retrouver rapidement des fichiers ou des documents spécifiques en temps voulu.
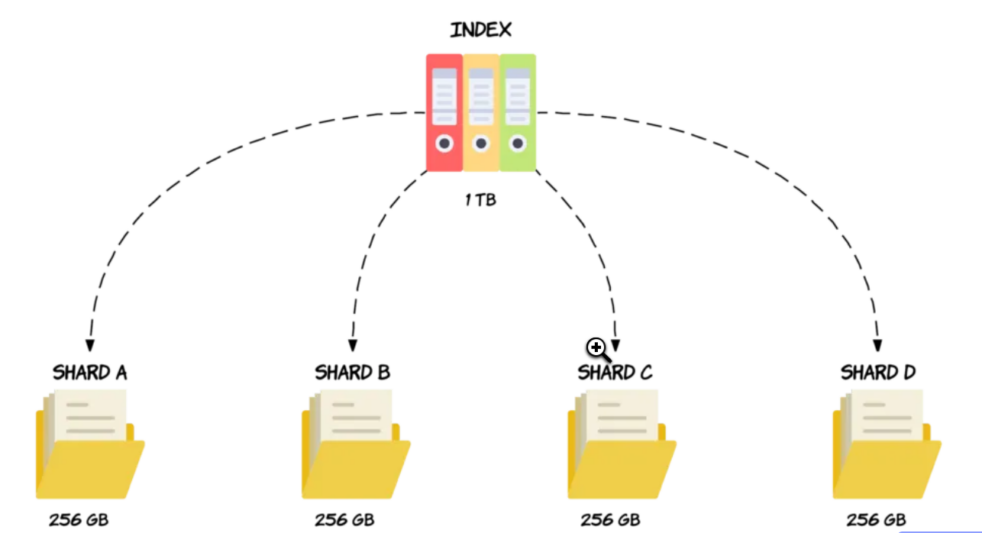

Crédit de l’image : Bo Andersen
Le type
Il s’agit d’une classification logique de l’index, semblable au concept de tables dans les bases de données relationnelles. Concrètement, Elasticsearch utilise les types pour catégoriser les documents.
Un document
Un document est une unité d’information de base qui peut être indexée. Elle est définie au format JSON (Javascript Object Notation) et possède un identifiant et un type d’index qui lui sont spécifiques.
Le mapping
Le mapping est un procédé consistant à définir la relation existant entre un document et ses champs. Il contient des informations telles que des champs de métadonnées, des listes de champs ou des attributs.
La partition (Shards ->Apache Lucene Index)
Traduit en anglais par shard, une partition est une partie constitutive d’un index. Les index, qui contiennent des documents JSON, sont horizontalement divisés en shards, tout comme les tables dans un SGBD sont partitionnées en lignes.
Ces shards ou partitions sont répartis dans les nœuds du cluster Elasticsearch. Ils améliorent les performances des requêtes grâce à la récupération parallèle et optimisent le temps de réponse du moteur.
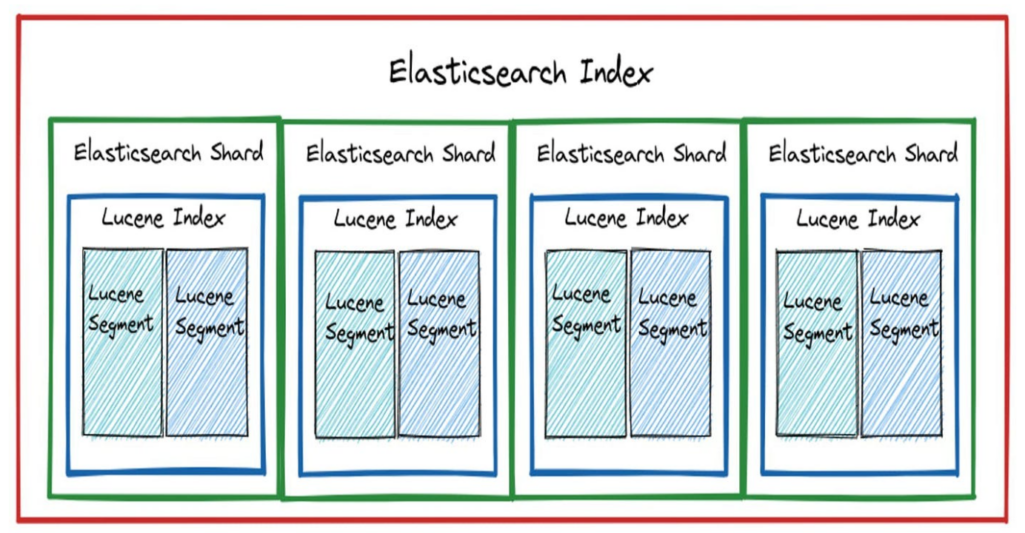
Crédit de l’image : Lakshya Bansal
La réplique
Les index et les partitions sont répliqués à travers les nœuds du cluster Elasticsearch pour augmenter la haute disponibilité des traitements en cas de panne dans l’environnement de production réseau/serveur.
Ces répliques permettent de paralléliser les traitements de recherche de contenu dans le cluster, ce qui accroît les capacités d’Elasticsearch.
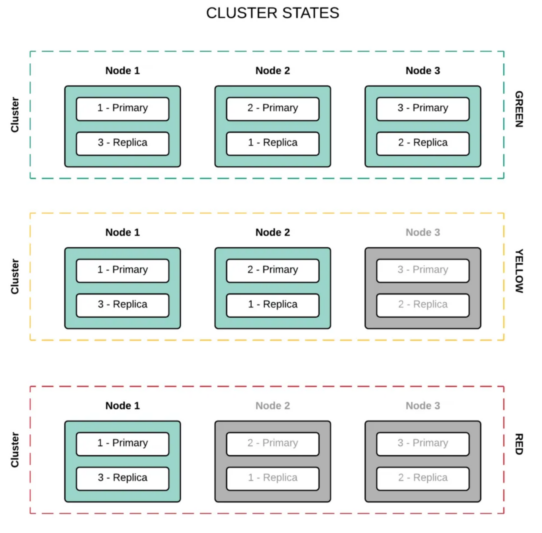
Crédit de l’image : Devopsideas
Le gateway
Le gateway est la méthode de stockage persistante de l’index Elasticsearch. Elle consiste, pour ce moteur, à stocker les données d’index en mémoire, puis à les conserver sur le disque dur quand la mémoire est pleine.
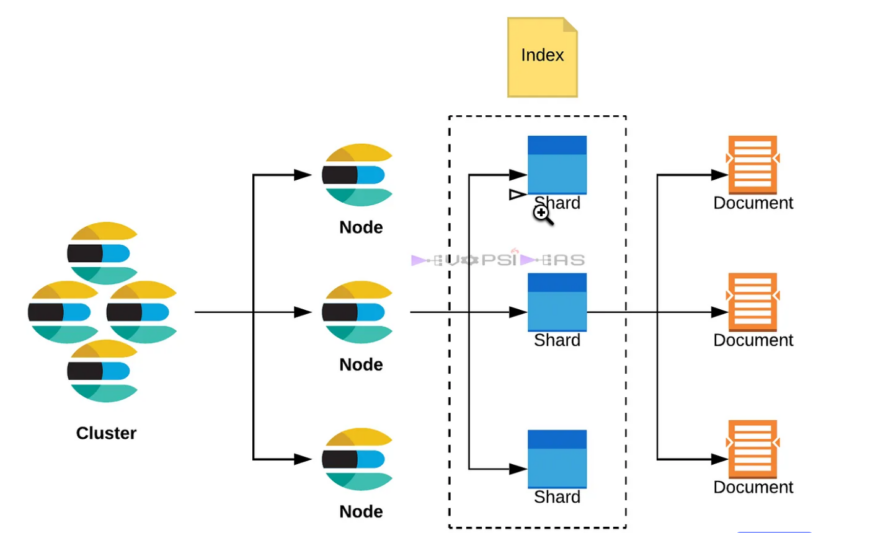
Crédit de l’image : Devopsideas
Les fonctions d’Elasticsearch
Très polyvalent, Elasticsearch propose à ses utilisateurs une riche palette de fonctionnalités, aussi pratiques les unes que les autres. Intéressons-nous brièvement à cinq d’entre elles.
Le moteur de recherche full-text
Elasticsearch exploite une structure appelée index inversé pour faire des recherches full-text très rapides. Un index inversé est constitué d’une liste des mots uniques qui apparaissent dans un document. Pour chaque mot, cet index possède le relevé de tous les documents JSON où il apparaît.
Pour créer un index inversé, il faut diviser le champ de contenu de chaque document en mots séparés (appelés termes ou tokens), puis créer une liste triée de tous les termes uniques.
Enfin, il faut lister dans quels documents chaque terme apparaît. Cette structure bien organisée est à l’origine de la pertinence des résultats obtenus avec ce moteur.
La résolution des requêtes complexes
Dès que leurs données sont indexées dans Elasticsearch, les utilisateurs peuvent lancer des requêtes complexes à partir de leurs données et se servir des agrégations pour obtenir des résumés complexes de leurs données.
Grâce à son Query DSL complet, Elasticsearch s’occupe facilement des demandes de recherche complexes. Aussi, il permet aux utilisateurs grâce à Kibana de créer des visualisations puissantes de leurs données, de partager des tableaux et de gérer la Suite Elastic.
La résolution des calculs complexes
Il est intéressant de noter qu’Elasticsearch pour Apache Hadoop propose un support technique de premier ordre pour Apache Storm. Il s’agit d’un système de calcul en temps réel distribué et open source.
Apache Storm facilite le traitement fiable de flux de données illimités et résout donc les calculs complexes. Il fait de vraies prouesses pour le traitement en temps réel.
La résolution d’opérations difficiles à résoudre pour les bases de données traditionnelles
Elasticsearch prouve sa puissance remarquable par sa capacité à résoudre aisément les opérations difficiles pour les bases de données traditionnelles. Cette fonctionnalité sera d’une grande utilité pour les utilisateurs ayant des besoins spécifiques.
Le secret de cette performance réside dans son architecture scalable associée aux nombreux API et outils en cluster intégrés dans son interface, mais aussi dans sa capacité à établir des liens entre les données.
La résolution du traitement des données de séries chronologiques
Elasticsearch propose des outils pratiques pour le traitement des données de séries temporelles. Ceux-ci offrent de nombreuses possibilités, telles que l’automatisation des processus grâce à des fonctionnalités comme la gestion du cycle de vie des index, les index gelés ou encore les cumuls.
Par ailleurs, avec la fonctionnalité de Machine Learning, l’utilisateur peut utiliser les informations disponibles pour extrapoler les comportements futurs de ses données et faire des prévisions. Il peut aussi effectuer des analyses automatiques et détecter les anomalies dans ses données.
Conclusion
En définitive, retenons qu’Elasticsearch est un moteur de recherche et d’analyse de données presque aussi puissant que Google tout en étant open-source. De plus, la mise en relation des différents concepts clés d’Elasticsearch ont simplifié la résolution des calculs complexes ainsi que le traitement des données de séries chronologiques.
 Opter pour la reconversion professionnelle dans l’entrepreneuriat
Opter pour la reconversion professionnelle dans l’entrepreneuriat
Leave a Reply