
« Les mauvais programmeurs se soucient du code. Les bons programmeurs se soucient des structures de données et de leurs relations. » — Linus Torvalds, créateur de Linux
Les structures de données sont des composantes essentielles du développement de logiciels. Leur connaissance est souvent évaluée pendant les entretiens de recrutement avec des développeurs.
Ce sont aussi de simples formats spéciaux d’organisation et de stockage des données, pas difficiles à comprendre.
Cet article de blog vous présente les 10 structures de données les plus courantes.
Il contient aussi des vidéos créées pour chacune de ces structures de données, ainsi que des liens vers des exemples de code correspondants, qui expliquent comment les implémenter en JavaScript.
Enfin, il contient des liens vers les challenges du programme freeCodeCamp pour que vous puissiez vous entraîner.
Notez que certaines de ces structures de données incluent une complexité temporelle en notation Grand O. Ce n’est pas le cas de toutes, car la complexité temporelle est parfois basée sur l’implémentation de la structure de données. Si vous souhaitez en savoir plus sur la notation Grand O, consultez mon article à ce sujet ou cette vidéo de Briana Marie.
Notez également que je vous explique comment implémenter ces structures de données en JavaScript, mais que vous n’aurez probablement jamais à les implémenter vous-même, sauf si vous utilisez un langage de bas niveau comme C.
JavaScript (comme la plupart des langages de haut niveau) intègre déjà des implémentations de la plupart de ces structures de données.
Toutefois, la connaissance de ces structures de données vous sera utile dans votre recherche d’emploi de développeur et lors de vos tentatives d’écriture de code haute performance.
Listes liées
La liste liée est l’une des structures de données les plus basiques. On la compare souvent à un tableau, car beaucoup d’autres structures de données sont implémentées avec un tableau ou une liste liée. Les deux méthodes présentent des avantages et des inconvénients.
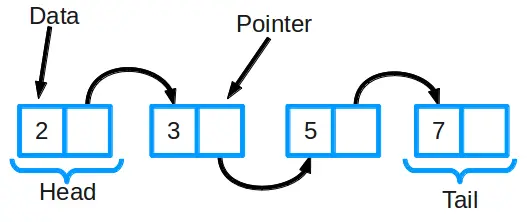
Représentation de liste liée (object ci-dessus)
Une liste liée se compose d’un groupe de nœuds qui, ensemble, représentent une séquence. Chaque nœud contient deux choses : les données réelles stockées (qui peuvent être n’importe quel type de données) et un pointeur (ou lien) vers le nœud suivant dans la séquence. Il y a aussi des listes doublement liées dans lesquelles chaque nœud comporte un pointeur vers l’élément suivant et l’élément précédent dans la liste.
Les opérations les plus basiques d’une liste liée sont l’ajout d’un élément à la liste, la suppression d’un élément de la liste et la recherche d’un élément dans la liste.
Voir le code pour une liste liée en JavaScript ici.
Linked list time complexity
| Algorithm | Average | Worst Case |
|---|---|---|
| Space | 0(n) | 0(n) |
| Search | 0(n) | 0(n) |
| Insert | 0(1) | 0(1) |
| Delete | 0(1) | 0(1) |
freeCodeCamp challenges
- Work with Nodes in a Linked List
- Create a Linked List Class
- Remove Elements from a Linked List
- Search within a Linked List
- Remove Elements from a Linked List by Index
- Add Elements at a Specific Index in a Linked List
- Create a Doubly Linked List
- Reverse a Doubly Linked List
Piles
Une pile est une structure de données de base dans laquelle vous pouvez uniquement insérer ou supprimer des éléments en haut de la pile. Elle ressemble à une pile de livres. Pour consulter un livre au milieu de la pile, vous devez d’abord retirer tous les livres qui se trouvent au-dessus.
La pile est basée sur le modèle dernier entré, premier sorti (LIFO). Cela signifie que le dernier élément ajouté à la pile est le premier à en sortir.


Représentation de pile
Il est possible d’effectuer trois opérations principales sur les piles : insérer un élément (push), supprimer un élément (pop) et afficher le contenu (pip, le plus souvent).
Voir le code pour une pile en JavaScript ici.
Stack time complexity
| Algorithm | Average | Worst Case |
|---|---|---|
| Space | 0(n) | 0(n) |
| Search | 0(n) | 0(n) |
| Insert | 0(1) | 0(1) |
| Delete | 0(1) | 0(1) |
freeCodeCamp challenges
Files d’attente
La file d’attente fonctionne un peu comme une file d’attente de supermarché. Le premier dans la file est le premier servi. Ici c’est le même fonctionnement.

Représentation de file d’attente (object ci-dessus)
Une file d’attente accède aux données sur le modèle premier entré, premier sorti (FIFO). Cela signifie que lorsqu’un nouvel élément est ajouté, tous les éléments ajoutés avant doivent être supprimés avant de pouvoir retirer ce nouvel élément.
Une file d’attente permet d’effectuer deux opérations principales : enqueue et dequeue. L’opération enqueue insère un élément à la fin de la file d’attente et l’opération dequeue retire le premier élément.
Voir le code pour une file d’attente en JavaScript ici.
Queue time complexity
| Algorithm | Average | Worst Case |
|---|---|---|
| Space | 0(n) | 0(n) |
| Search | 0(n) | 0(n) |
| Insert | 0(1) | 0(1) |
| Delete | 0(1) | 0(1) |
freeCodeCamp challenges
Ensembles
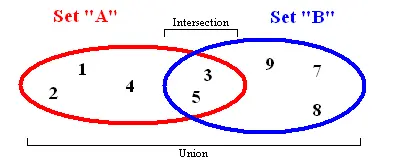
Représentation d’ensemble (object ci-dessus)
La structure de données de type « set » (ensemble) stocke des valeurs dans un ordre non spécifique et sans les répéter. Outre l’ajout et la suppression d’éléments à un ensemble, d’autres fonctions « set » importantes fonctionnent avec deux ensembles à la fois.
- Union : combine les éléments de deux ensembles différents et renvoie le résultat sous la forme d’un nouvel ensemble (sans doublons).
- Intersection : à partir de deux ensembles, cette fonction renvoie un autre ensemble comprenant tous les éléments qui font partie des deux ensembles.
- Différence : renvoie une liste d’éléments contenus dans un ensemble mais PAS dans un autre ensemble.
- Sous-ensemble : renvoie une valeur booléenne qui montre si tous les éléments d’un ensemble sont inclus dans un autre ensemble.
Voir le code pour implémenter un ensemble en JavaScript ici.
Challenges freeCodeCamp
- Créer une classe set
- Supprimer un ensemble
- Taille de l’ensemble
- Appliquer une union sur deux ensembles
- Appliquer une intersection sur deux ensembles
- Appliquer une différence sur deux ensembles de données
- Appliquer un contrôle de sous-ensemble sur deux ensembles de données
- Créer et ajouter des ensembles dans ES6
- Supprimer des éléments d’un ensemble dans ES6
- Utiliser .has et .size sur un ensemble ES6
- Utiliser Spread et Notes pour l’intégration d’objet Set() ES5
Cartes
Une carte est une structure de données qui stocke les données par paire clé/valeur, où chaque clé est unique. Une carte est parfois appelée un tableau associatif ou un dictionnaire. Elle est souvent utilisée pour la recherche rapide de données. Les cartes permettent d’effectuer les tâches suivantes :
Représentation de carte (object ci-dessus)
- ajout d’une paire à la collection
- suppression d’une paire de la collection
- modification d’une paire existante
- recherche d’une valeur associée à une clé particulière
Voir le code pour implémenter une carte en JavaScript ici.
freeCodeCamp challenges
Tables de hachage
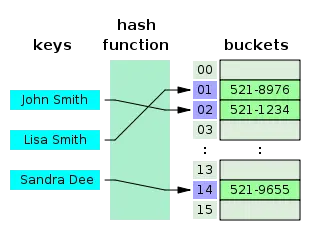
Représentation d’une table de hachage et d’une fonction de hachage (object ci-dessus)
Une table de hachage est une structure de données de type carte qui contient des paires clé/valeur. Elle utilise une fonction de hachage pour calculer un index dans un tableau d’alvéoles (buckets ou slots, en anglais), à partir duquel la valeur souhaitée peut être trouvée.
La fonction de hachage prend généralement une chaîne en entrée et génère une valeur numérique en sortie. La fonction de hachage doit toujours produire le même numéro de sortie pour une même entrée. Lorsque le hachage de deux entrées produit la même sortie numérique, on parle de collision. L’objectif est de réduire les collisions au minimum.
Donc, quand vous entrez une paire clé/valeur dans une table de hachage, la clé est exécutée via la fonction de hachage et transformée en nombre. Cette valeur numérique est ensuite utilisée comme clé réelle de stockage de la valeur. Lorsque vous tentez d’accéder à nouveau à la même clé, la fonction de hachage traite la clé et renvoie le même résultat numérique. Le nombre est ensuite utilisé pour rechercher la valeur associée. On obtient ainsi un temps de recherche moyen très performant de O(1).
Voir le code d’une table de hachage ici.
Hash table time complexity
| Algorithm | Average | Worst Case |
|---|---|---|
| Space | 0(n) | 0(n) |
| Search | 0(1) | 0(n) |
| Insert | 0(1) | 0(n) |
| Delete | 0(1) | 0(n) |
freeCodeCamp challenges
Arbre de recherche binaire
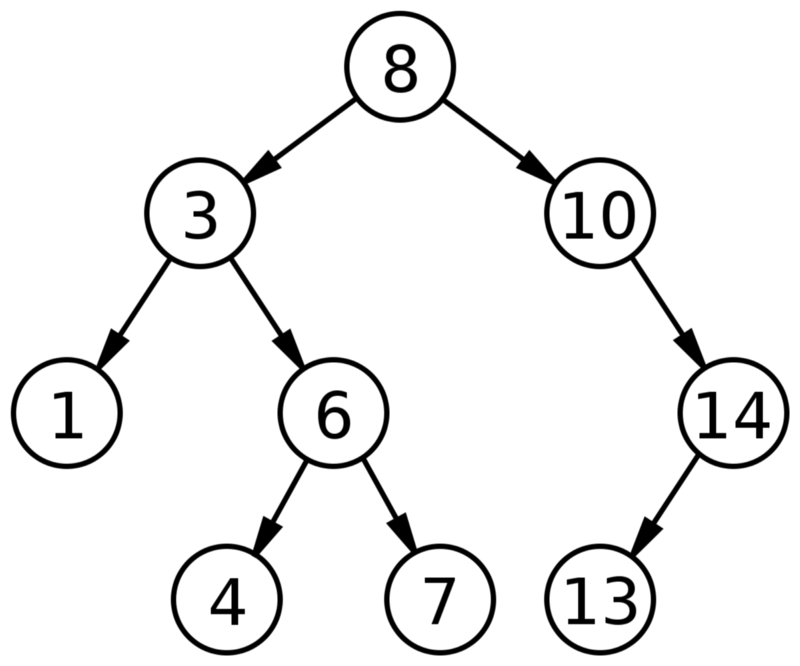
Arbre de recherche binaire (object ci-dessus)
Un arbre est une structure de données composée de nœuds qui présente les caractéristiques suivantes :
- Chaque arbre a un nœud racine (au sommet).
- Le nœud racine a zéro ou plusieurs nœuds enfants.
- Chaque nœud enfant a zéro ou plusieurs nœuds enfants, et ainsi de suite.
Un arbre de recherche binaire présente en plus les deux caractéristiques suivantes :
- Chaque nœud a jusqu’à deux enfants.
- Pour chaque nœud, les descendants de gauche sont inférieurs au nœud en cours, qui est lui-même inférieur aux descendants de droite.
Les arbres de recherche binaire accélèrent la recherche, l’ajout et la suppression d’éléments. En raison de leur configuration, chaque comparaison permet en moyenne aux opérations d’ignorer au moins la moitié de l’arbre. Ainsi, chaque recherche, insertion ou suppression occupe un temps proportionnel au logarithme du nombre d’éléments stockés dans l’arbre.
Voir le code pour un arbre de recherche binaire en JavaScript ici.
Binary search time complexity
| Algorithm | Average | Worst Case |
|---|---|---|
| Space | 0(n) | 0(n) |
| Search | 0(log n) | 0(n) |
| Insert | 0(log n) | 0(n) |
| Delete | 0(log n) | 0(n) |
freeCodeCamp challenges
- Find the Minimum and Maximum Value in a Binary Search Tree
- Add a New Element to a Binary Search Tree
- Check if an Element is Present in a Binary Search Tree
- Find the Minimum and Maximum Height of a Binary Search Tree
- Use Depth First Search in a Binary Search Tree
- Use Breadth First Search in a Binary Search Tree
- Delete a Leaf Node in a Binary Search Tree
- Delete a Node with One Child in a Binary Search Tree
- Delete a Node with Two Children in a Binary Search Tree
- Invert a Binary Tree
Trie
Le trie (prononcé « try » comme en anglais) ou arbre préfixe est un type d’arbre de recherche. Le trie stocke les données par échelon, chaque échelon étant un nœud dans le trie. Les tries sont généralement utilisés pour stocker des mots qui accélèrent la recherche, comme une fonctionnalité de saisie semi-automatique.
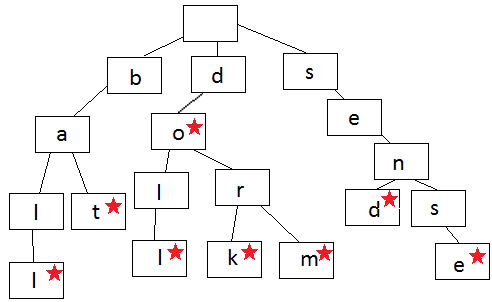
Représentation de trie (object ci-dessus)
Chaque nœud d’un trie de langage contient une lettre d’un mot. Pour épeler un mot, lettre par lettre, vous devez suivre les branches du trie. Les échelons bifurquent lorsque l’ordre des lettres diverge des autres mots dans le trie ou lorsqu’un mot se termine. Chaque nœud contient une lettre (données) et une valeur booléenne qui indique si le nœud est le dernier nœud d’un mot.
En regardant l’image, vous pouvez former des mots. Commencez toujours au niveau du nœud racine au sommet, puis progressez vers le bas. Le trie de cette illustration contient les mots ball, bat, doll, do, dork, dorm, send, sense.
Voir le code pour un trie en JavaScript ici.
freeCodeCamp challenges
Tas binaire
Le tas binaire est une autre structure de données de type arbre. Chaque nœud a au plus deux enfants. Il s’agit par ailleurs d’un arbre complet. C’est-à-dire que tous les niveaux sont entièrement remplis jusqu’au dernier, et le dernier est rempli de gauche à droite.
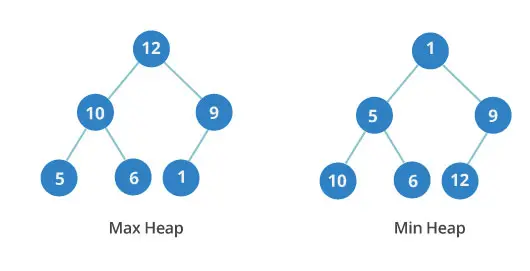
Représentations de tas minimum et maximum (object ci-dessus)
L’ordre entre les niveaux est important, mais l’ordre des nœuds sur un même niveau ne l’est pas. Dans l’image, vous voyez que le troisième niveau du tas minimum a les valeurs 10, 6 et 12. Ces nombres ne sont pas dans l’ordre.
Voir le code pour un tas en JavaScript ici.
Binary heap time complexity
| Algorithm | Average | Worst Case |
|---|---|---|
| Space | 0(n) | 0(n) |
| Search | 0(1) | 0(log n) |
| Insert | 0(log n) | 0(log n) |
| Delete | 0(1) | 0(1) |
freeCodeCamp challenges
- Insert an Element into a Max Heap
- Remove an Element from a Max Heap
- Implement Heap Sort with a Min Heap
Graphe
Les graphes sont des collections de nœuds (également appelés sommets) et les connexions (appelées arêtes) qui les relient. Les graphes sont également appelés des réseaux.
Un réseau social est un exemple de graphe. Les nœuds sont les personnes et les arêtes sont les relations.
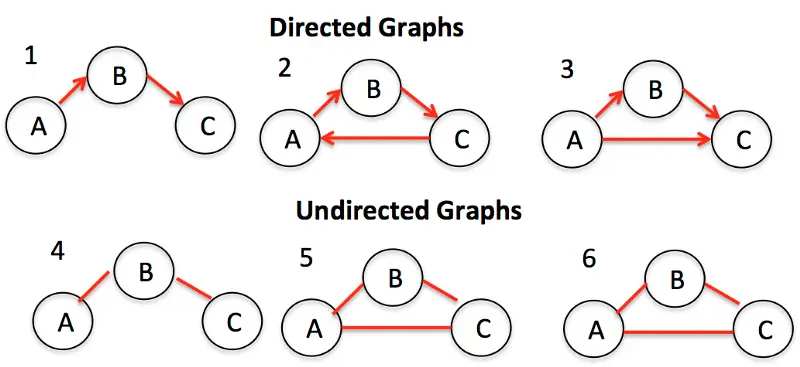
Il existe deux types de graphes : orientés et non orientés. Les graphes non orientés sont des graphes dans lesquels les arêtes ne sont pas orientées entre les nœuds. Les graphes orientés sont des graphes dans lesquels les arêtes sont orientées.
Un graphe est souvent représenté sous forme de liste d’adjacence et de matrice d’adjacence.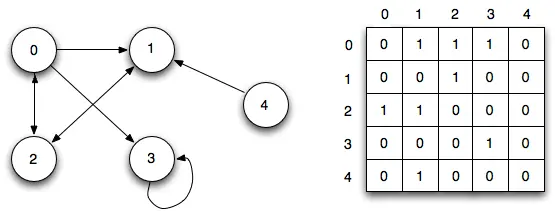
Graphe de type matrice d’adjacence (object ci-dessus)
Une liste d’adjacence peut être représentée sous forme de liste dans laquelle le côté gauche est le nœud et le côté droit liste tous les autres nœuds auxquels il est connecté.
Une matrice d’adjacence est une grille de nombres, dans laquelle chaque ligne ou colonne représente un nœud différent dans le graphe. Le nombre qui apparaît à l’intersection d’une ligne et d’une colonne indique la relation. Les zéros signifient qu’il n’y a pas d’arête ou de relation. Les uns signifient qu’il y a une relation. Les nombres supérieurs à 1 sont utilisés pour indiquer différents poids.
Les algorithmes de parcours sont des algorithmes qui traversent ou explorent des nœuds dans un graphe. Les principaux types d’algorithmes de parcours sont les algorithmes de parcours en largeur et en profondeur. Ils permettent notamment de déterminer la proximité des nœuds par rapport à un nœud racine. Découvrez comment implémenter un algorithme de parcours en largeur en JavaScript dans la vidéo ci-dessous.
Binary search time complexity
| Algorithm | Time |
|---|---|
| Storage | O(|V|+|E|) |
| Add Vertex | O(1) |
| Add Edge | O(1) |
| Remove Vertex | O(|V|+|E|) |
| Remove Edge | O(|E|) |
| Query | O(|V|) |
freeCodeCamp challenges
Plus d’informations
Le livre Grokking Algorithms est la meilleur référence sur ce sujet si vous n’avez aucune connaissance en structures de données/algorithmes et que vous n’avez pas de formation en informatique. Il contient des explications faciles à comprendre et des illustrations ludiques réalisées à la main (par l’auteur qui est aussi développeur principal chez Etsy) pour expliquer les structures de données présentées dans cet article.
Cet article a été traduit en français avec l’approbation de l’auteur: Beau Carnes. Article original publié:
https://www.freecodecamp.org/news/10-common-data-structures-explained-with-videos-exercises-aaff6c06fb2b/
 Interview des experts informatiques – Hugo Briand, Blockchain Lead
Interview des experts informatiques – Hugo Briand, Blockchain Lead
Leave a Reply